前言
本文是由笔者所原创的 《概率论与数理统计》系列文章之一,
本文为作者原创作品,转载请注明出处;
本博文中涉及有关笔者所新创的概念,术语,设计图,分析模型以及分析思路等均属笔者的知识产权,严禁用于商业用途;版权所有,违者必究。
概述
条件概率看似简单,其实认真思考起来会有很多的陷阱;笔者本着从思考问题的本质出发,去探求条件概率的本质是什么,带大家去了解教科书上不曾介绍的东西;这样,当我们了解了条件概率的本质和奥秘,一切相关问题便迎刃而解了。
说明,在本文开始阐述以前,笔者约定,
假设有一事件 A,则符号 |A| 表示该事件的样本点的个数,该表达方式是参照钟开莱在《初等概率学》中的表示方式;
若一个事件可以表述为 A={w|w={xi,yi,zi}} 的情况,笔者将 xi 表示样本点的第一个元素,yi 表示样本点的第二个元素…
条件概率
定义
大学教科书上的定义:条件概率既是指当某个事件发生的前提下,另一个事件发生的概率;
其实这个定义并不完全准确,很多时候,当某个事件没有发生的情况下,一个事件的概率也会发生变化;关键是看评估这个事件的概率的前提是什么,既是针对什么样的样本空间进行评估的,这才是条件概率真正的涵义所在;所以,笔者给出一个更为准确的定义,如下,
条件概率是指在某个特定前提条件下(既一个特定的样本空间 S )的特定的概率;比如,通常情况下,我们有事件 B 的概率 P(B)=BΩ,但是如果我们将事件 B 所参照的样本空间 Ω 变为 S,且 S 是 Ω 的子集,B 与 S 存在交集 BS,这时 B 相对于前提条件 S 的概率为
P(B)′=|B∩S||S|=|B∩S||Ω||S||Ω|=P(B∩S)P(S)
数学上,将上式中的 P(B)′ 表示为 P(B|S),所以我们有
P(B|S)=P(B∩S)P(S)=|B∩S||S|⋯⋯①
所以归纳起来,条件概率就是指某个事件 B 对样本空间 Ω 的某个子集 S 的概率,而与其它某个事件是否真的发生与否无关,唯一变化的是计算概率的样本空间发生了改变而已。
乘法公式
由 ① 式我们可以求解到两事件交集 AB 的概率,令 ① 式中的 S 为 A,得
P(AB)=P(A)P(B|A)=P(A)⋅P(AB)P(A)⋯⋯②
笔者解读,要理解乘法公式,
首先,关键要理解 A∩B、 A 以及 B 所对应的样本空间 Ω 是什么,否则便不能真正的理解到与条件概率相关的乘法公式;要知道的是,A 和 B 都只是中间步骤,而 A∩B 才是最终结果事件,令 A∩B=D,那么显然 D 所对应的样本空间 Ω 才是 A∩B、 A 以及 B 所共同的样本空间。更为详细的论述可以参考男孩女孩例子中的描述。
其次,求解 D 的概率既是相当于求解 D 相对于 Ω 的比例,从数学逻辑上可以这样来理解,笔者通过绘制如下的一张概念图来进行描述,
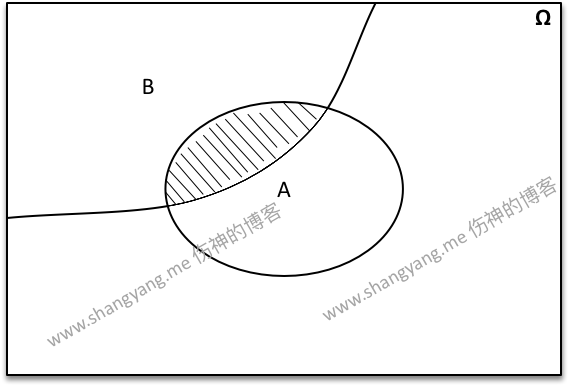
P(AB) 要求解的就是图中阴影部分与样本空间 Ω 的比例,有
P(AB)=|A∩B||Ω|下面我们再来看看通过乘法公式既 P(AB)=P(A)P(B|A) 背后的数学意义是什么, 首先求出 A 占 Ω 的比例 p1,然后求出 B∩A 所占 A 的比例 p2,所以实际上要求解的结果就是 p1⋅p2,那么 p1⋅p2 想要表述的是什么呢?
p1⋅p2=P(A)⋅P(B|A)=|A||Ω|⋅|A∩B||A|=|A∩B||Ω|所以,可以看到,P(A)⋅P(B|A) 实际上求解的就是 A∩B 相对于 Ω 的概率;而 P(B|A) 实际上求解的是 A∩B 相对于 S 的概率;
笔者要特别强调的是,一种几乎被所有教程所忽略的是,乘法公式中使用到了条件概率公式 P(A)P(B|A),而条件概率公式中隐含了一个非常重要的约定,既是一种先后顺序,因为 B 是相对于 A 的条件概率,那么就是说 A 是 B 的前提,或者说 A 比 B 先发生,所以这里隐含的事件顺序就是 A 在 B 之前出现,A 是 B 的前提;但是由事件相交的交换律有 A∩B=B∩A 所以必然有 P(AB)=P(BA),也就是说,A 和 B 发生的先后顺序换句话说,谁作为谁的前提并不影响最终的结果,也就是说在以条件概率为基础的前提下来计算 AB 的概率,无论事件 A 和 B 谁先发生或者说谁作为谁的前提,都不会影响最终 AB 的概率;但得有个前提,既是 Ω 在 A 和 B 的过程中都不发生改变,若 Ω 发生了改变,那么 AB 的概率会随 A 和 B 的先后顺序而改变,这个正是罐子模型中深入研究的部分,该部分在教科书中有浓墨重彩的描述,这里就不再赘述了;最后,有关上述的数学表达式背后的数学逻辑是什么,笔者这里就不再描述了,有兴趣的同学可以自行研究。
一般乘法公式
若 P(A1⋯An)>0,则
P(A1⋯An)=P(A1)P(A2|A1)P(A3|A1A2)⋯P(An|A1⋯An−1)⋯③证明,因为 P(A1)≥P(A1A2)≥⋯≥P(A1⋯An−1)>0 ,然后将 ③ 式右边项通过条件概率公式逐项展开,我们得到
P(A1)⋅P(A1A2)P(A1)⋅P(A1A2A3)P(A1A2)⋯P(A1⋯An)P(A1⋯An−1)=P(A1⋯An)将左式的分子和分母逐项的消去记得 P(A1⋯An)=P(A1⋯An) 所以左右量是相等;
笔者补充,这个证明通过数学表达式的方式非常容易证明,但是撇开数学表达式,背后的数学逻辑到底是什么呢?其实和乘法公式一样,一般乘法公式实际上只是对乘法公式的一般性扩展,从乘法公式的论证过程中,不难发现 P(A1)P(A2|A1)P(A3|A1A2)⋯P(An|A1⋯An−1) 实际上求解就是 A1∩A2∩⋯∩An 相对于 Ω 的比值。可以用下面这张概念图来表示该逻辑,图中阴影部分便是全概率公式所要求解比例部分;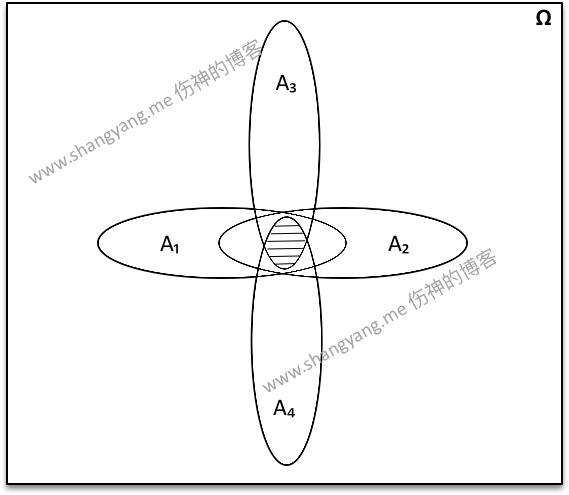
例子
民意测验
对某学院里的全体学生进行民意测验,以了解他们对某个总统候选人的态度。设 D 表示支持他的那些人。现在学生的总人数为 Ω,且可以按照各种方式进行交叉分类;例如按照性别、年龄、种族等进行分类,设有如下的分类
A=女性,B=黑人,C=到选举年龄的人
由此 Ω 可以被分为 8 个子集 ABC,AB¯C,…,¯A¯B¯C,那么如果我们需要求得适合投票年龄的并表示赞成黑人男性的概率是多少?
P(D|¯ABC)=P(¯ABCD)P(¯ABC)
并且通过 P(A)=AΩ 可以继续推出
P(¯ABCD)P(¯ABC)=¯ABCDΩ¯ABCΩ=¯ABCD¯ABC
备注,要使得上述等式成立,必须约定概率 P 是针对 Ω 的比值;而概率学正式这样约定的,只是教科书上没有阐明而已,
P(D|¯ABC)=¯ABCD¯ABC
(要注意的是,上式中的 ¯ABCD 并非表示各个样本点集相乘,而是表示相交既 ¯A∩B∩C∩D),从这个表达式我们可以知道,求解条件概率的结果并不需要真的计算求得分子和分母相对于 Ω 的概率,而是只需要求得其对应的样本点集的数量然后直接进行相除即可。那么,下面我们再求解一下适合投票年龄的并表示赞成男性赞成的概率是多少?
P(D|¯AC)=P(¯ACD)P(¯AC)
从这个例子中我们要知道的是,同样一个事件 D 在以不同的样本空间 S 作为前提条件进行参考的情况下,所求得的概率是不相等的;上述的两个例子正好说明了这一点,假设事件 D 为赞成投票这个事件,但是在参照的样本空间 S 发生变化的前提下,所求得的事件 D 的概率是不相同的。上述的描述还是过于理论化,能不能有这样的一张直观的概念图,通过它能看够一目了然其中的逻辑关系呢?由此,笔者分别针对上述两种不同的情况分别绘制了如下的两张概念图,
适合投票年龄的并表示赞成黑人男性的概率 P(D|¯ABC)=P(¯ABCD)P(¯ABC)=¯ABCD¯ABC,用图解的方式描述如下,
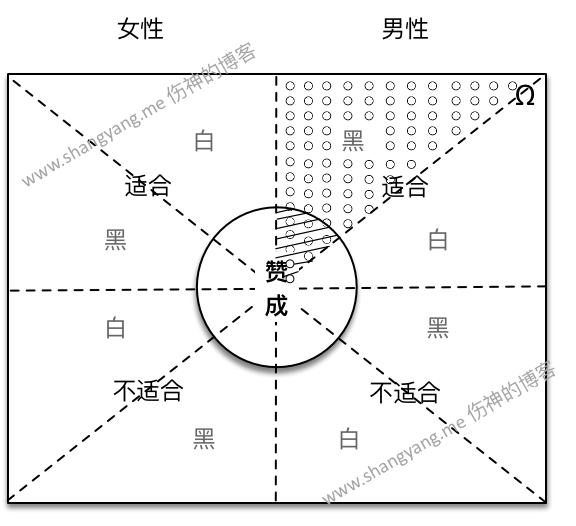
首先,整个样本集 Ω 被划分成男性和女性两个部分,假设分别对应左半方块和右半方块;
然后,男性和女性所对应的样本点集合又分别被划分为两个部分,适合和不适合两个部分;
其次,适合和不适合部分又被分为两个部分,既是黑人和白人两个部分;
这样,通过上述的三个维度进行划分,Ω 总共被分为了 8 个部分;
(备注,实际情况的各个部分不应该是均等分开,但是为了绘图的方便和直观,假设是均等分开的)
现在,让我们来求解适合投票年龄并表示赞成的黑人男性的概率是在哪个部分?可以让所有表示赞成的人(样本点)全部往里走并且让其它不赞成的统统往外走,最终所有赞成的人在中心的位置汇聚成了这样的一个圆,这时,中间的这个圆所代表的所有样本点既表示所有表示赞成的样本点集合并将此样本点集合记为事件 D;显然,表示赞成的适合投票年龄的黑人男性的样本点既是上图中用斜线所画出的阴影部分所表述的部分。那么条件概率 P(D|¯ABC) 表述的是什么呢?先来看表达式 ¯ABC,表示男性、黑人并且到了适合选举年龄的人的交集,这个交集正好对应的就是右上角标注为“黑”的部分也就由无数个小圆点所标注的阴影部分,将该部分记为事件 S 表示一个新的样本空间;然后 S 又分为赞成和不赞成的两个部分,那么显然,该部分与圆圈内的样本集相交的部分也就是图中用斜线所标注的阴影的部分既表示适合投票年龄中表示赞成的黑人男性的样本点 ¯ABCD,又因为 ¯ABC=S,所以 ¯ABCD=SD;由此条件概率 P(D|¯ABC)=¯ABCD¯ABC=P(¯ABCD)P(¯ABC)=P(D|S)=SDS=P(SD)P(S) 既是表示事件 D 在以 S 为前提条件下的条件概率,换句话说,用数学的语言表述为,也就是事件 D 与 S 的交集既 DS 在 S 中的概率是多少;用图解的方式即可表述为 P(D|S)=由斜线所组成的阴影的部分由小圆点组成的阴影的部分。最后要注意的是,从这里我们得到一个重要的关系既 P(D|S)≤P(D) (注意,当 P(D|S)=P(D) 的时候表示 D 是独立事件,特点就是条件 S 的变化不影响事件 D 的概率,注意,P(D)=DΩ,也就是说有等式 P(D)=DΩ=DSS=P(D|S),有关独立事件更为详细的阐述笔者将会在后续的文章中进行描述,不过这里可以看出端倪,既是如果 D 是相对于 S 是独立事件,那么必然有 S=Ω)。
- 同样的,适合投票年龄的并表示赞成的所有男性的概率 P(D|¯AC)=P(¯ACD)P(¯AC) 笔者将其图解如下,
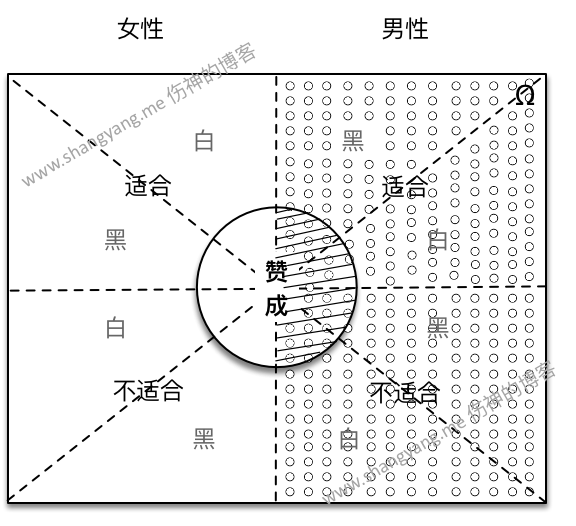
设 S 且 S=¯AC 既表示男性的部分,右图中小圆点所组成的阴影部分表示,D∩S 由图中斜线部分所组成的阴影部分所表示,那么条件概率 P(D|S) 等于图中阴影部分既 SD 与 S 之间的比值,所以有 P(D|S)=SDS=P(SD)P(S)。用图解的方式可以直观的描述为,条件概率 P(D|S)=由斜线所组成的阴影的部分由小圆点组成的阴影的部分,这里要注意 S 既新的样本空间的变化。
男孩女孩
考虑有两个孩子的全部家庭,假定生男孩与女孩是等可能的。因此,样本空间可用 4 个点来表示,
Ω={(bb),(bg),(gb),(gg)}
其中 b = 男孩,g = 女孩;每一对的次序是指年龄的大小,年龄大的在前面;
若从 Ω 中随机的选出一个
家庭 β ,发现它有一个男孩,问该家庭 β 的另外一个小孩仍然是男孩既该家庭是 (bb) 的概率有多大?
书本上给出的解题都比较的笼统,笔者这里给出自己的更为详尽的解题思路,首先,要搞懂我们求解的是什么,既是家庭 β 是 (bb) 的概率有多大?其次,别忘了,在求解该事件的概率之前,有一个前置条件,那就是要求所选择出来的家庭 β 已经有一个男孩了,然后在此基础之上再计算家庭 β 是两个男孩的概率;所以,显然,典型的求解条件概率的问题,因此,我们设前置条件为事件 A 既表示有一个男孩的家庭,设要被求解的条件概率为事件 B,我们令,事件 A = {ω|在ω中有一个男孩}事件 B = {ω|在ω中有两个男孩}
那么事件 B 的条件概率为
P(B|A)=P(AB)P(A)=ABA显然,A∩B=1,A=3,所以有
ABA=13=P(AB)P(A)=P(B|A)如果令 A=S,那么有
P(B|A)=P(B|S)=P(BS)P(S)=BSS=13所以,事件 B 的概率就是要求解事件 B 相对于新的样本空间 S 的比值,S 表示的正是已经有一个男孩的家庭的样本点集合。
若从这些家庭中随机的选择一个男孩 α,问它有一个亲哥或者亲弟的概率有多大?下面是笔者自己的比较详尽解题思路,
首先,#2 与 #1 最大的区别是,#1 求解的是某个家庭是两个男孩的概率,而 #2 所要求解的是某个男孩有亲兄弟概率,所以,一个是以家庭为单位来求解其对应的概率,而另外一种则是以孩子为单位来求解相应的概率,所以抽样的方式从本质上是不同的。其次,同样,这是一个求解条件概率的问题,为什么呢?因为最终要求解的概率既某个孩子 α 的亲哥或者亲弟的概率,而这个孩子 α 是有前置条件的,既 α 首先必须是一个男孩;所以,这也是一个典型的求解条件概率的问题,同样我们令事件 A = {ω|ω是一个男孩}事件 B = {ω|ω的亲哥或者亲弟是男孩}那么事件 B 的条件概率为
P(B|A)=P(AB)P(A)=ABA
显然,若以孩子为样本点那么样本空间 Ω 总计有 8 个样本点,所以有 A=4,A∩B=2,所以求得求得 B 的条件概率为
P(B|A)=A∩BA=24=12=P(AB)P(A)
上面的详细过程是如何求解出来的呢?要注意的是,Ω 中的样本点可以用下面的方式进行表述,
Ω={b⋅b,b⋅g,g⋅b,g⋅g}笔者将上述样本空间中的样本点部分使用 ∙ 来替代样本点分隔符 , 的目的在于,表述两个样本点之间存在依赖关系(表示这两个样本点同属于一个家庭中的成员),所以,当有了上面这个特殊的样本空间 Ω 以后,很明显事件 A 总共有 4 个样本点既 A=4,而事件 B 的样本点为 A∩B=2,之所以要求交集是因为 B 是从 A 中进行选择的;因此,我们得到 P(B|A)=A∩BA=24=12。所以,若令 A=S,那么有
P(B|A)=P(B|S)=A∩BS=24=12
上面的两种情况描述了典型的条件概率的所出现的应用场景,既是首先根据某种条件从 Ω 中筛选出符合条件的样本点使其构成新的样本空间 S,然后,再根据某种条件从新的样本空间 S 中继续筛选出我们想要的样本点 {ω},最后,所计算的概率也就是去计算 {ω} 相对于 S 的比例。但是,还有一种非常特殊的情况,来看下面这种情况,
还是以孩子为抽样对象进行抽样,我们来求解这样的一种概率,首先在 Ω 中随机抽取一个男孩(不放回),将该事件定义为 A,然后再从 Ω 中随机抽取一个孩子且不放回,将该事件定义为 B,问 B 是男孩且是 A 的亲弟或者亲哥的概率?下面是笔者自己的解题思路,
在求解 B 的概率之前,我们先来考察一下整个事件 C 的概率,事件 C 是什么?既是 A∩B,事件 C 即表示先取出一个男孩 A,然后再随机取出一个男孩 B 且 B 是 A 的亲哥或者亲弟的整个事件;但为什么事件 C 不是 A∪B 呢?其实很简单,因为最后取得的 B 必须是 A 的一部分,所以整个事件 C 只能是 A∩B,所以我们有事件 C=A∩B,根据乘法原理,我们很容易求得事件 C 的概率,
P(C)=P(AB)=2×18×7=28×17=128事件 C 要求解的是取到有兄弟关系的两个样本点既 {b,b} 相对于样本空间的概率,所以事件 A 有 2 种取法,事件 B 只有 1 种取法,所以根据乘法原理,A 和 B 可能性为 2×1,而样本空间 Ω 总共有 8×7 个样本点,所以最终求得事件 C 的概率为 256=128。我们回头来看看事件 B 的概率是什么该如何求解,因为 B 的选择受制于 A,所以显然,B 一定是一个以 A 为前提条件的条件概率;先不管背后的数学逻辑是什么,我们直接来套用条件概率的公式计算一下结果,
P(B|A)=P(AB)P(A)=12814=128×41=17
可以看到,求解 B 的条件概率 P(B|A) 与使用乘法公式计算出步骤 B 的可能性的概率是出奇的吻合,都是 17,但是背后的数学逻辑是什么呢?我们对以家庭为样本点的样本空间 Ω′ 中的每个孩子进行编号,有
Ω′={(b1b2),(b3g1),(g2b4),(g3g4)}那么我们可以得到以孩子为样本点的样本空间,
Ω″={b1,b2,b3,g1,g2,b4,g3,g4}显然,只有 b1 和 b2 才可能互为亲兄弟;所以,要得到事件 C,那么 A 只能从 {b1,b2} 中选择,所以有 2 种可能性,但是如果我们按照此逻辑继续分析下去的话,就会出现问题,因为由求解 B 的条件概率公式 P(B|A)=P(AB)P(A)=ABA,若令 A=SA,那么 B|A 的样本点既是从新的样本空间 SA 中去采样,但是,我们知道 SA={b1,b2},而 B 又只有一种取法,所以我们将会得到错误的结果既 P(B|A)=12,这也是在这种场景下使用条件概率进行分析的前提下非常容进入的思维误区;笔者也曾深陷其中,曾因此一度深深的怀疑过条件概率的正确性。得出该错误结论的根源在于,对此类事件的样本空间一开始没有搞清楚;
那么正确的思路又该是怎样的呢?Ω″ 的确是事件 A 的样本空间,但是如果它同时是某个事件的子事件,那么这个样本空间 Ω″ 同样是 Ω 的一个子集,我们知道,概率学上规定,求解某个事件的概率必须是该事件与样本空间 Ω 的比值(当然,条件概率除外),所以,在求解事件 A 的概率之前,必须搞清楚当前所计算的概率所参照的样本空间 Ω 到底是什么?所以,我们要问的是,哪个事件中的所有样本点代表此时的样本空间 Ω,对,答案就是由事件 C 所对应的样本空间,那么该样本空间是什么呢?事件 C 是要随机抽取两个孩子作为样本点并判断该样本点是亲兄弟的概率,所以它的样本空间中的样本点是由两个孩子所构成的,既
Ω={(b1b2),(b1b3),(b1b4),(b1g1),(b1g2),(b1g3),(b1g4)(b2b1),(b2b3),(b2b4),(b2g1),(b2g2),(b2g3),(b2g4)(b3b1),(b3b2),(b3b4),(b3g1),(b3g2),(b3g3),(b3g4)⋯⋯(g4b1),(g4b2),(g4b3),(g4b4),(g4g1),(g4g2),(g4g3)}这就是事件 C 的所对应的样本空间 Ω,总共包含 56 个样本点,每一个样本点中孩子的先后顺序分别表示第一次和第二次抽取的顺序;这下,我们再来分析 B 的条件概率 P(B|A) 就容易多了,先来看事件 A,由前面的分析可知,A 只能从 {b1,b2} 中选择,所以,事件 A 总共有 14 个样本点,因此有
P(A)=AΩ=1456=14设 A=SA,所以有,
SA={(b1b2),(b1b3),(b1b4),(b1g1),(b1g2),(b1g3),(b1g4)(b2b1),(b2b3),(b2b4),(b2g1),(b2g2),(b2g3),(b2g4)}所以,要能够得到事件 C,同样 B 只能从 {b1,b2} 中选择,只是要注意的是,因为 B 是第二步,所以只能从样本点的第二个元素去获取,因此,满足条件的只有 {(b1b2),(b2,b1)} 两个样本点,因此,求得 B 相对于前提条件 SA 的条件概率为
P(B|A)=214=17终于,在笔者几经周折以后,终于得到上述通过条件概率的方式求解 P(B|A) 的条件概率的正确方法;
简化方式
最后,笔者想要补充的是一种求解 P(A) 的简化方式,如果每一次都要先求出 Ω 然后再去求解 A 的概率会显得比较的复杂,在求解事件 A 的概率的时候,可以将样本空间按照如下的方式做一下调整
Ω‴={b1b2,b1b3,b1b4,b1g1,b1g2,b1g3,b1g4b2b1,b2b3,b2b4,b2g1,b2g2,b2g3,b2g4b3b1,b3b2,b3b4,b3g1,b3g2,b3g3,b3g4⋯⋯g4b1,g4b2,g4b3,g4b4,g4g1,g4g2,g4g3}在考虑事件 A 的时候,可以将样本空间中每一个样本点的第二个元素(既孩子)可以理解为第一个元素的某种附带关系,而且这种附带关系不计入样本点中,因此样本空间 Ω 在计算事件 A 的时候就被化简了,就只有 8 个样本点了既 {b1,b2,b3,b4,g1,g2,g3,g4} ,因此事件 A 的概率很容易求得 P(A)=28;但需要注意的是,不能使用 Ω‴ 来计算 B 的条件概率 P(B|A),否则直接进入前面笔者所描述的思维误区。
笔者使用上述的三个用例囊括了条件概率所常见的三种场景,其实三种场景都可以归为一类,既是通过前置事件 A 从样本空间 Ω 中筛选出样本空间的子集 S 作为新的样本空间,然后事件 B 是以 A 为前提条件的条件概率事件,那么有 P(B|A)=P(BA)P(A)=P(BA)P(S),这其实就回到了条件概率的定义;只是要注意的是,如果取样的方式和对象不同,则对应的样本空间 Ω 不同,进而使得求解的过程和方式也不同。
黑球红球
假设一个罐子中有 3 个黑球和 2 个红球,求第一次取出一个黑球并放回以后,第二次取到红球的概率是多少?
解,
设事件 A 为第一次取到一个黑球,事件 B 为第二次取到一个红球,事件 C 为整个事件既当第一次取到一个黑球以后再取到一个红球也就是 A∩B;显然 Ω 为事件 C 所对应的样本空间,我们有
Ω={(b1b1),(b1b2),(b1b3),(b1r1),(b1r2)(b2b2),(b2b1),(b2b3),(b2r1),(b2r2)(b3b3),(b3b1),(b3b2),(b3r1),(b3r2)(r1r1),(r1r2),(r1b1),(r1b2),(r1b3)(r2r2),(r2r1),(r2b1),(r2b2),(r2b3)}
上述求样本空间 Ω 的思路与男孩女孩中的第 3 个例子的求解思路一致,唯一的区别是,这里允许放回,所以,在第二次抽取的时候有可能会抽取到自己;上图中,假设黑球和红球分别由 b 和 r 来表示,并且为每一个球贴上了序号,这样我们就得到了事件 C 所对应的样本空间 Ω,其中每一个样本点中元素所出现的先后顺序分别表示第一次和第二次抽取的顺序;在求得了 Ω 以后,我们通过如下的步骤来计算 P(C) 既是 P(AB),
首先,我们来求解 A 的概率,A 表示样本点中第一个球是黑球的样本点,所以 A 总共有 15 个样本点,所以有
P(A)=|A||Ω|=1525=35再次,我们来求解 B 的概率,显然 B 的概率是以 A 为条件的条件概率 P(B|A),令 A=S,所以新的样本空间 S 总共有 15 个样本点,
S={(b1b1),(b1b2),(b1b3),(b1r1),(b1r2)(b2b2),(b2b1),(b2b3),(b2r1),(b2r2)(b3b3),(b3b1),(b3b2),(b3r1),(b3r2)}事件 B 表示从 S 中第二次抽取到红球,所以 B 总共有 6 个样本点,所以
P(B|A)=P(B|S)=615=25补充备注(以下内容可跳过),
从这里可以看出事件 B 具有独立性,因为 P(B|A)=P(B)=25,我们将 B 当做一个孤立事件既无条件事件来考察,既是直接从一个罐子里取出一个红球而没有任何的前提条件既没有 A 事件的发生,那么 |Ω|=5,此时有 P(B)=25,因此可见 B 的概率并不受条件 A 的影响,因此 B 在条件 A 的前提下 B 是一个独立事件;
最后,我们来求解事件 C 既 AB 的概率是多少?因为事件 C 是事件 A 和 B 的交集,所以有
P(C)=P(AB)=P(A)P(B|A)=35×25=625
验证,
下面,我们使用传统的求解概率的方式来求解并验证一下事件 C 的概率,使用乘法定理,该过程分为两个步骤,分别为步骤 A 取一个红球和步骤 B 取一个红球,步骤 A 有 3 种可能,而步骤 B 有 2 中可能,因为是放回抽样,所以两个步骤的总体样本空间 Ω=5×5=25,因此事件 C 的概率
P(C)=3×225=625
得证;
总结,
在使用条件概率来求解某个事件的概率的时候,首先要考察清楚的是样本空间 Ω 是多少?
罐子模型
假设一个罐子中有 b 个黑球,r 个红球,每次从罐子中抽取 1 个球然后放回,并且在放回的同时再放入 c 个同色球,d 个异色球;若 Bi 表示“第 i 次取出的是黑球”,Rj 表示“第 j 次取出的是红球”,那么我们分别来求解 P(B1R2R3)、P(R1B2R3) 和 P(R1R2B3) 的概率。
解,
B1R2R3 表示的是第 1 次抽取得到的是黑球,第 2 次抽取得到的是红球,第 3 次抽取得到的还是红球;令 B1R2R3=D,事件 D 的概率通过乘法公式非常容易求解,该抽取过程总共分为三个步骤,第一个步骤 B1 抽取到黑球的可能性为 bb+r,第二个步骤 R2 抽取到红球的可能性为 r+db+c+r+d(注意,新增了 c 个黑球和 d 个红球),第三个步骤 R3 抽取到红球的可能性为 r+2db+2c+r+2d ,而 D 所对应的样本空间 Ω 有 (b+r)(b+c+r+d)(b+2c+r+2d) 种可能,所以我们可以非常容易的求得
P(B1R2R3)=(b)(r+d)(r+2d)(b+r)(b+c+r+d)(b+2c+r+2d)=bb+r⋅r+db+c+r+d⋅r+2db+2c+r+2d
由一般乘法公式我们有,
P(B1R2R3)=P(B1)⋅P(R2|B1)⋅P(R3|B1R2)=P(B1)⋅P(B1R2)P(B1)⋅P(B1R2R3)P(B1R2)
由上述两个表达式我们可以猜得 P(B1)=bb+r,P(R2|B1)=r+db+c+r+d,P(R3|B1R2)=r+2db+2c+r+2d,教科书上讲到这里就为止了,留给了我们诸多的疑点,这些条件概率是怎么求得的?比如 P(R2|B1)=r+db+c+r+d,按照常规的推理,有第一步 B1 求得的新的样本空间 SB 应该是 b 才对,那么P(R2|B1) 不就应该等于 r+db 吗?当然这个想当然的错误的推论笔者在男孩女孩中的第 3 个用例中已经浓墨重彩的解释过了,是因为事件 B1 所考虑的样本空间出了问题,笔者这里不再赘述,只是告诉读者,这里给我们留下了诸多的疑点,为什么 P(R2|B1) 就等于了 r+db+c+r+d 呢?下面笔者给出详细的论证过程,
- 令 B1∩R2∩R3=D,那么事件 D 所对应的样本空间 Ω 才是事件 B1 的样本空间,Ω 中样本点由三个小球组成,第一个小球为黑色,其余两个小球为红色,构成了一个有 (b+r)(b+c+r+d)(b+2c+r+2d) 个样本点的样本空间 Ω;
- 但是,如果直接从 Ω 中去求解由 B1 所构成的新的样本空间 SB 会相当的复杂,所以,求解过程必须简化,该简化方式笔者在男孩女孩的第三个用例中有过详细的描述,这里不再赘述,总体而言,就是在求解 B1 的概率的时候,可以将 B1 看做是一个孤立事件来对待,既可以将 B1 的样本空间 Ω′ 看做是由 b+r 个样本点所组成,而在求解 B1R2 的时候,同样可以将 B1R2 看做是一个孤立事件,既可以将 B1R2 的样本空间 Ω″ 看做是由 (r+b)(b+c+r+d) 个样本点所构成的;通过这样简化以后,再去求解相关的条件概率的时候,相应的就会容易许多了;
试着来求解一下 P(R2|B1) 的条件概率,
P(R2|B1)=P(B1R2)P(B1)由 #2 有事件 R2|B1 的样本空间 Ω″ 由 (r+b)(b+c+r+d) 个样本点所组成,那么要求解 R2|B1 的条件概率,重要的是要求得两个事件 B1 和 B1∩R2 分别在 Ω″ 中的比值,
➭ 求解 B1 在 Ω″ 中的比值
笔者在思考如何求解该比值的过程中,两个样本空间给了我十足的灵感,一个是黑球红球中所使用到的样本空间
Ω={(b1b1),(b1b2),(b1b3),(b1r1),(b1r2)(b2b2),(b2b1),(b2b3),(b2r1),(b2r2)(b3b3),(b3b1),(b3b2),(b3r1),(b3r2)(r1r1),(r1r2),(r1b1),(r1b2),(r1b3)(r2r2),(r2r1),(r2b1),(r2b2),(r2b3)}可见,将上述矩阵的行数设为 m,将列数设为 n,假设我们要求解黑球 B 所占 Ω 的比例 P(B),可见黑球的总数量为 3,它既表示黑球在矩阵的总共有的行数,所以我们得到 B 总共由 3⋅n 个样本点所构成,所以,得到 P(B)=3⋅nm⋅n=3m 已知 m=5,所以可以求得 P(B)=35;所以,通过这个例子给了我一种直觉,那就是某个事件 X 所占样本空间的比例可以通过行数 m、列数 n 以及当把该事件当做孤立事件来看待的时候的样本点的个数 c 求得,显然有
P(X)=c⋅nm⋅n让我们回到罐子模型的这个例子中来,首先,由前置条件 B1 决定了 Ω″ 中的样本点的第一个元素必须是从最开始的由 r+b 个黑球或红球中所取得的,当取第二次既是到了 R2 的时候,虽然多增加了 c+d 个球,但新增的球不能出现在 Ω″ 样本点的第一个元素的位置上,只能出现在后续的位置上,原因很显然,不再赘述;所以,当事件 R2 发生时,笔者将样本空间 Ω″ 抽象为下图所示,
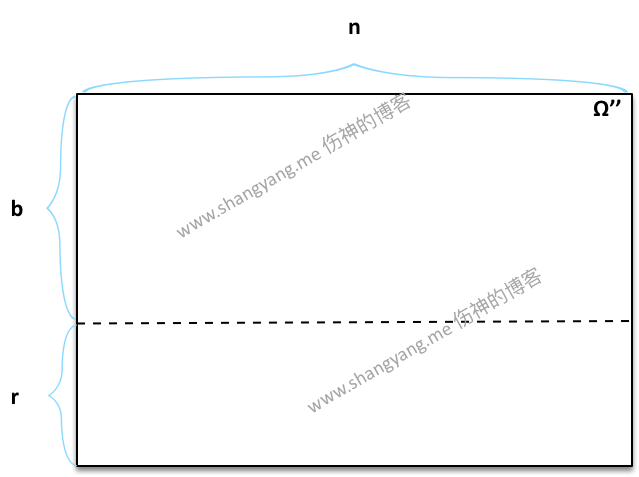
如图,样本空间 Ω″ 给划分成了 b⋅n 和 r⋅n 两个部分,且显然 n=b+c+r+d,之所以可以这样画的前提是,只会有 b 个黑球和 r 个红球出现在 Ω″ 的样本点的第一个元素的位置上,也就是说这些样本点只能表示为 {b∗} 和 {r∗} 两种形式,由此,我们可以求得在 R2 的条件下,B1 的概率为
P(B1)=b⋅n(b+r)⋅n=bb+r➭ 求解 B1∩R2 在 Ω″ 中的比值,
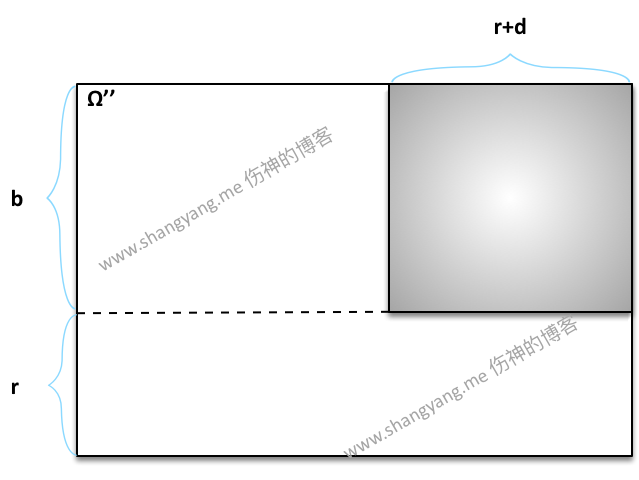
如图,B1∩R2 的样本点由上图阴影部分所示,于是求得
P(B1∩R2)=(r+d)⋅b(b+r)⋅n➭ 求解 P(B1|R2),
通过上述的力证以后,我们可以自信的得到
P(B1|R2)=P(B1∩R2)P(R2)=(r+d)⋅b(b+r)⋅nbb+r=r+dn=r+db+c+r+d由此,为什么 为什么 P(R2|B1) 就等于了 r+db+c+r+d 因此得证;另外,还有一种求解思路更为简单,既是在 R2 做为条件下,令 B1=S,那么这个时候我们有 S=b⋅n,而 B1∩R2=(r+d)⋅b,所以
P(B1|R2)=B1∩R2S=b⋅(r+d)b⋅n=r+db+c+r+d
笔者推荐使用后一种方式,因为这种方式更贴近条件概率的定义;
当求得了 P(B1R2) 以后,我们可以继续使用上述的方式严格按照条件概率的方式来求解 P(B1R2R3),不再赘述;当 P(B1R2R3) 求解出来以后,按照相同的逻辑便可以求解 P(R1B2R3) 和 P(R1R2B3) 的概率了;
其实,不使用上述的简化模型,而考虑全局的样本空间 Ω 同样也可以求得 P(B1R2),笔者将相关问题的求解模型绘制如下,
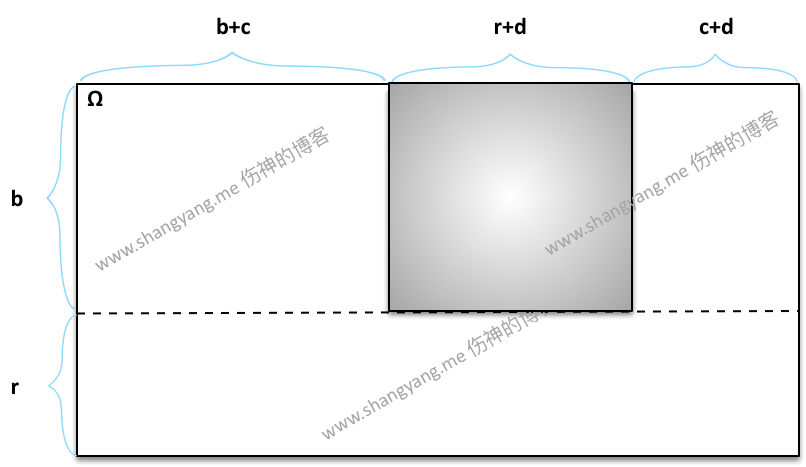
根据条件概率的定义,同样有,
P(B1|R2)=B1∩R2S=b⋅(r+d)b⋅n=r+db+c+r+d
最后,笔者要重点提示的是,如果不需要深入研究条件概率并寻找到其它的一些特性和共性的情况下,如果只需要求解 P(ABC) 的概率,那么直接使用古典的乘法定理来求解更为方便和快捷。
全概率公式
全概率公式 1
若 Ω 可以被分割为 B1,B2,⋯,Bn 个互不相容的事件,且有 B1∪B2∪⋯Bn=⋃ni=1Bi=Ω ,如果 P(Bi)>0,i=1,2,⋯,n, 则对任一事件 A 有
P(A)=n∑i=1P(Bi)P(A|Bi)
上面便是教科书上对全概率公式的定义,我们先来理解一下背后的数学逻辑是什么?笔者先把上述的公式调整一下,可以得到
P(A)=n∑i=1P(Bi)P(A|Bi)=n∑i=1P(BiA)=P(B1A)+P(B2A)+⋯+P(BnA)=|B1A|+|B2A|+⋯+|BnA||Ω|
所以,非常的明显,A=(B1∩A)∪(B2∩A)∪⋯∪(Bn∩A),所以有
P(A)=|A||Ω|=|(B1∩A)∪(B2∩A)∪⋯∪(Bn∩A)||Ω|
所以其背后的数学逻辑可以用下面这张概念图来进行表述,

图中阴影部分便是事件 A 的样本点集,随着样本空间被 B1、B2、⋯、Bn 所切分,随之而言,事件 A 同样被切分成 A1、A2、⋯、An 各部分,且有 A1=A∩B1,A2=A∩B2,A3=A∩B3 ・・・An=A∩Bn,所以有
P(A)=|A||Ω|=|A1|+|A2|+⋯+|An||Ω|=|B1A|+|B2A|+⋯+|BnA||Ω|=P(B1A)+P(B2A)+⋯+P(BiA)=n∑i=1P(BiA)=n∑i=1P(Bi)P(A|Bi)
举一个最简单最简单的例子,教科书中总喜欢堆叠复杂的例子,而忽略了概念的本质,笔者给出一个再简单不过的例子来说明这一切,假设有从 1 到 12 个实数,因此样本空间为
Ω={1,2,34,5,67,8,910,11,12}假设,Ω 被 B1、B2、B3 和 B4 四个事件所切分且 B1 表示上述样本空间的第一行样本点既 {1,2,3},同样 B2、B3 和 B4 分别表示第二行、第三行和第四行的样本点;因此有 B1∪B2∪B3∪B4=Ω,现在令任一事件 A 表示偶数,很显然 P(A)=|A||Ω|=612=12
现在我们使用全概率公式的逻辑来求解,
P(B1)P(A|B1)=14⋅23P(B2)P(A|B2)=14⋅13P(B3)P(A|B3)=14⋅23P(B4)P(A|B4)=14⋅13根据全概率公式,我们有
P(A)=P(B1)P(A|B1)+P(B2)P(A|B2)+P(B3)P(A|B3)+P(B4)P(A|B4)=612=12上述的例证,笔者隐含了一个重要的概念,就是事件的定义,至此到该系列之前的所有章节,事件都被定义为一种人为的行为,比如抽样行为,第一抽黑球还是红球等等,因此,似乎事件的定义是由人的行为所限制的,其实不然;实际上事件是由随机变量所定义的,是由随机变量所构成的样本点集合,也就是说,当一个 Ω 确定以后,为了分析该样本空间中样本点的特性,可以将任意的样本点汇聚成一个事件来进行分析;相关部分,笔者将会在后续有关随机变量的文章中专门论述;
再举一个例子,笔者比较喜欢黑球红球这个例子,先来回顾一下与之相关的样本空间如下所述,
Ω={(b1b1),(b1b2),(b1b3),(b1r1),(b1r2)(b2b2),(b2b1),(b2b3),(b2r1),(b2r2)(b3b3),(b3b1),(b3b2),(b3r1),(b3r2)(r1r1),(r1r2),(r1b1),(r1b2),(r1b3)(r2r2),(r2r1),(r2b1),(r2b2),(r2b3)}首先来找一个事件使其所有的互不相容子事件能够将 Ω 划分成多个独立的部分,黑球红球中已经定义好的事件 A 和 B 都不能满足,这里,我们来定义一个新的事件 D 表示第一个球可以取任意的球既红球或者黑球,显然,事件 D 可以朗阔样本空间中的所有样本点,又令 D1、D2、D3、D4 和 D5 是 D 的子事件且分别表示上述样本空间中的第 1 行、第 2 行、第 3 行、第 4 行和第 5 行的样本点,那么我们现在使用全概率公式来求解 B (既第二个球为红球)的概率,
P(D1)P(B|D1)=15⋅25P(D2)P(B|D2)=15⋅25P(D3)P(B|D3)=15⋅25P(D4)P(B|D4)=15⋅25P(D5)P(B|D5)=15⋅25根据全概率公式,我们有
P(B)=P(D1)P(B|D1)+P(D2)P(B|D2)+P(D3)P(B|D3)+P(D4)P(B|D4)+P(D5)P(B|D5)=1025=25从这个例子中我们要看到的是,全概率公式到底想要告诉我们什么东西?其实就是事件 B 相对于 Ω 的概率,因为 D=Ω;
全概率公式 2
若 B∪¯B=Ω,则对任一事件 A 有
P(A)=P(B)P(A|B)+P(¯B)P(A|¯B)
这个公式就是全概率公式 1
P(A)=n∑i=1P(Bi)P(A|Bi)
的另一种写法而已,本质上没有任何的变化;若令 B=B1,¯B=B2,那么有
P(A)=2∑i=1P(Bi)P(A|Bi)=P(B1)P(A|B1)+P(B2)P(A|B2)=P(B)P(A|B)+P(¯B)P(A|¯B)
得证。
笔者补充,全概率公式 1 与全概率公式 2 看似描述的是同一个公式,但是实际上所描述的问题的侧重点不同,全概率公式 1 的侧重点是通过同类事件的子类对某个目标事件进行描述,而全概率公式 2 描述问题的重点是通过对两个不同类别的事件的集合对某个目标事件进行的描述;
记忆技巧
全概率公式如果死记硬背的话不太容易记住,隔一段时间非常容易忘记,而全概率公式又是贝叶斯公式的一部分,所以全概率公式如果忘记了那么贝叶斯公式也就会记不住了;那么能不能直接透过公式看到里面的逻辑呢?然后再通过逻辑直接反推公式呢?那么笔者带大家继续深挖一下这个公式,
P(A)=n∑i=1P(Bi)P(A|Bi)再来回顾一下这个公式背后所对应的逻辑图,
对照上面这张概率图,要记忆住全概率公式,其实只需要记住下面两个步骤,
- 首先,P(A|Bi) 表示的是 |A1∩1Bi||Bi|,是 A 相对于 Bi 的概率,但是我们知道,全概率公式所要求解的是 A 相对于 Ω 的概率,所以,剩下的问题是,如何通过 P(A|Bi) 来推导出 P(A)?
- 根据公式,大家很容易知道,就是将 P(A|Bi) 乘以 P(Bi) 即可,其实背后的数学逻辑也很简单,既是,A 是 Bi 中的一部分,而 Bi 是 Ω 的一部分,这个一部分关系正好由 P(Bi) 表示,所以 |Ai||Bi|⋅P(Bi) 自然就表示 Ai 相对于 Ω 的比例记为 P(Ai),显然 ∑ni=1P(Ai)=P(A)
总结
当有事件 A 的时候,若要求解 P(A),有下述三种方式,
- 当 A 是独立事件的时候,有 P(A);
- 当有条件事件 B 的时候,使得 Ω=B 的时候,有 P(A)=n∑i=1P(Bi)P(A|Bi)
- 当有条件事件 B 的时候,使得 Ω=B∪¯B 的时候(既是 BA 事件所对应的样本空间),有 P(A)=P(B)P(A|B)+P(¯B)P(A|¯B)
上述三种方式求解的 P(A) 均相等,唯一的区别是,三个公式所计算 A 的概率的样本空间不同;所以,以后当求解 A 的概率的时候,上述三个方式都是等价的,个中的变化需牢记于心。
贝叶斯公式
先来看看高等教育出版社出版的《概率论与数理统计教程》第二版中的定义,
在乘法公式和全概率公式的基础上立即可推得一个很著名的公式,
P(Bi|A)=P(Bi)P(A|Bi)∑nj=1P(Bj)P(A|Bj)
设 B1,B2,⋯,Bn 是样本空间 Ω 的一个分割,B1,B2,⋯,Bn 互不相容,且 ⋃ni=1Bi=Ω,如果 P(A)>0,P(Bi)>0,i=1,2,⋯,n,则
说实话,当笔者第一看到这个公式的时候,一头雾水,j 是什么?怎么会突然多出一个变量 j,难道是对 B 使用 j 再次划分?那么 i 呢?对此,教科书上只负责给出这样一个玄而又玄的公式,并没有做任何的解释;至此,笔者便放弃了使用高等教育出版社出版的教程《概率论与数理统计教程》第二版来继续学习概率了,因为里面的内容的确让人很着急,而且有些内容是丈二摸不着头脑;真可怜了一帮学数学的大学生子弟们,只想说,学不懂真的不是你们的错!看看钟开莱所著《初等概率论》中对贝叶斯公式是如何定义的,很简单
假定 Ω=∑nBn,且 B1、B2、⋯、Bn 将 Ω 划分为了不相交集合的一个分割,则对任何集合 A,设 P(B)>0 我们有 P(Bn|A)=P(Bn)P(A|Bn)∑nP(Bn)P(A|Bn)
备注,因为笔者习惯了将贝叶斯公式的 B 写在前面,所以上述的公式中,笔者将 B 与 A 的顺序按照自己的习惯交换了一下,求证过程很简单,
双方乘以 P(A) 既得到
P(A)⋅P(Bn|A)=P(A)⋅P(Bn)P(A|Bn)∑nP(Bn)P(A|Bn)=P(A)⋅P(Bn|A)
所以得证;
可以看到,钟开莱所著的《初等概率论》中明确的指明了只有一个变量既是 n,所以由此可以看出,《概率论与数理统计教程》中,i 和 j 相等,所以只有一个变量,而不是两个变量;由此,笔者断定,《概率论与数理统计教程》将一个简单问题搞复杂了,关键是,这个给初学者造成了极大的困扰;但是,笔者要说的是,上述的公式还不是贝叶斯的全部,只是其中一部分,通过笔者对全概率公式两种方式进行的深入分析以后,得出结论,实际上贝叶斯公式的定义有如下两种方式,
贝叶斯公式 1
这种方式和钟开莱所定义一致,只是笔者换种数学形式对其进行描述,
设 B1,B2,⋯,Bn 是样本空间 Ω 的一个分割,B1,B2,⋯,Bn 互不相容,且 ⋃ni=1Bi=Ω,如果 P(Bi)>0 且 i=1,2,⋯,n,则
P(Bi|A)=P(BiA)P(A)=P(Bi)P(A|Bi)∑ni=1P(Bi)P(A|Bi)
抛开数学公式,我们来看看背后的数学逻辑是什么?该公式的应用场景对应于全概率公式 1,可以用如下的概念图予以描述
如图,贝叶斯公式 P(Bi|A) 可以看做是 |Bi∩A| 与 |A| 的比值;
结果和原因
对,其样本空间模型与全概率公式 1 中的一致,样本空间对应的就是 B 的样本点集,在这种样本空间的模型下,隐含了一个重要的前提,那就是 A⊂B;钟开莱在他的《初等概率论》中提到了一个非常有趣的现实中的例子,假设某人 A 被谋杀了,对应有 5 个嫌疑人 B={B1、B2、B3、B4、B5},试问哪个作案嫌疑最大?实际上就是分别对 B 中的样本点求 P(Bi|A),看谁的概率最大;若其中 Bi 表示原因,A 表示结果,那么也就相当于是要求解出,谁作为原因得到结果的可能性最大?那为什么非要用贝叶斯公式来求解呢?直接使用条件概率公式求解不也一样?是因为在人类的实践活动中,通常只知道结果(的概率)但并不知道原因(的概率),所以,才会使用贝叶斯公式进行求解;但是到底何为结果?笔者继续使用上面的这个例子来进行解释,虽然有点有悖道德伦理,但是这的确是一个很能说明问题的例子;笔者将自己所思考的问题模型整理如下,
- 假设民警办案,对上述 B 中的每个嫌疑人逐个进行详细的走访、调查和追踪,得到 Bi 是坏人的可能性为 P(Bi),
- 然后以 Bi 为条件对象,继续深入调查,得出结论,它谋杀 A 的可能性为 P(A|Bi),
- 好了,我们有了上述的两个
结论( 既已知 P(Bi) 和 P(A|Bi) ),在此前提下,试问五个嫌疑人中,谁谋杀的可能性最大?这个问题既是要求解出 P(Bi|A);
因此,结论 P(Bi) 和 P(A|Bi) 就是结果,由此可见该结果通常能够通过人类的实验或者通过人类的认知和实践是可以判断和总结出来的;P(Bi|A) 则最终通过此结果所要推导出来的原因,所以上述的例子所描述的问题可以归纳为到底是由什么原因导致了该结果,在人类的实践过程中,通常原因是未知的,所以我们需要通过结果来推断出原因;从上述的推导过程中,可知 Bi 和 A|Bi 是人类通过实践过程中所获得的结果且也是贝叶斯公式所必须的结果,但是为什么书本上却单单只将 A 定义为结果呢?而又显然,Bi|A 才是要求解的原因,但又为什么书本上却直接将 Bi 定义为原因呢?
先回答第二个问题,既是为什么将 Bi 定义为
原因,那是因为 Bi 是我们社会认知中的事,所以,无论用数学表达式 Bi|A、Bi∩A 或者 Bi 都是表示的这件事,具体的描述参考笔者在第一篇文章《基础介绍》中的小节现实世界 ↔︎ 数学规律的内容;再来回答第一个问题,既 P(Bi) 和 P(A|Bi) 都表示试验
结果,那为什么书本上单单将 A 定义为结果呢?其实笔者这里的疑虑是正确的,从公式中,结果的确包含两个部分,既 A 和 Bi,等等,刚刚不是说 Bi 是原因,这里怎么又说成了结果?这里不自相矛盾了?其实并不矛盾,这里的 Bi 是从社会认知的角度去定义的,如果从数学定义上去描述,那么是 P(Bi|A) 才是最终要求解的原因,而 P(Bi) 表示这里的结果,两者在数学定义上是不同的,但是在社会认知学上,可以认为数学上的不同定义 P(Bi|A) 和 P(Bi) 都是对同一件事的两个不同维度上的描述;所以,从社会认知学上,这件事同时表示结果和原因,只是结果使用数学表达式 P(Bi) 表示,而原因是通过数学表达式 P(Bi|A) 表示的;
所以综上所述,贝叶斯公式中的原因和结果事件其实都是通过社会认知学上所定义的事来进行描述的,所这样,就不再有定义上的矛盾了;不仔细弄清楚上述的这些定义,是不可能真正理解贝叶斯公式中的原因和结果事件的定义的。
Ok,写到这里,笔者才算是长舒了一口气,才能自信的说自己算是对贝叶斯公式有了正确的认识和理解了;希望读者和我有同样的感受;下面我们再一起来感受以下贝叶斯公式 2 给我们所带来的奇妙之旅。
先验和后验概率
书本上将 P(Bi) 定义为先验概率,而将 P(A|Bi) 定义为后验概率;继续使用谋杀案作为例子,
- 民警通过对嫌疑人的前期摸排观察,通过判断他们是不是坏人,从数学上既是得出他们是不是坏人的概率 P(Bi),这就叫做
先验概率,就是判断这些人是否是坏人,然后判断其是否有有作案动机; - 当某些嫌疑犯 Bi 的
先验概率很大且符合预期以后,那么我们就对这几个重点嫌疑犯 Bi 进行更进一步的深入调查,于是,我们将 Bi 与被害者 A 联系起来一起进行分析,既是以 A 为条件来分析 Bi 是杀人犯的可能性,这就叫做后验概率;
笔者写到这里,不经感慨,笔者自己也不知道哪来的突发灵感,能够通过这样的一个浅显的例子将这么复杂的逻辑表示得这么的清楚,总之之前对笔者而言玄而又玄的先验和后验概率,现在对我而言,就是那么简单;其实总结起来,先验和后验概率就是将人类通过日常认知事物的方式用数学逻辑进行了抽象,想想,如果我们要判断某些物品 B 是否属于 A?我们将如何进行判断呢?首先,我们会对 B 本身做一些观察,做一些前期的检查,然后将某些可能性较大的物品挑选出来,这个动作在数学上将其定义为先验概率既 P(B),然后再将这些可能性较大的疑似物品 B 与 A 进行比对,这个动作在数学上既是以 A 为条件来计算 B 的概率,叫做后验概率既 P(B|A),一切就是那么简单;写到这里,笔者又不经感慨,其实数学并没有那么神秘,它就是对人类的认知逻辑通过数学的手段进行抽象和归纳,所以,最重要的其实还是人类认知事物的逻辑知识,既逻辑学;
贝叶斯公式 2
设 B∪¯B=Ω,假设 P(A)>0,我们有
P(B|A)=P(BA)P(A)=P(B)P(A|B)P(B)P(A|B)+P(¯B)P(A|¯B)
同样先抛开数学公式,我们来看看其背后的数学逻辑是什么?该公式的应用场景对应于全概率公式 2,可以用如下的概念图予以描述
样本空间分为 B 和 ¯B 两个部分,A 是 Ω 中的任意一个事件,且 A 与 B 有交集与 ¯B 也有交集;贝叶斯公式 2 求解的正式在 Ω 空间下,B∩A 与 A 的比值;这没有什么好奇怪的,不就是理所当然吗?有什么好多说的呢?坐稳了,笔者将描述这种情况下的重点了,还是以笔者在贝叶斯公式 1 中所介绍的谋杀案为例子,同样 B 表示嫌疑人,¯B 表示疑是嫌疑人的人,但还不是嫌疑人的人;A 同样表示某人被谋杀了这个事件;这下好玩了,相比于贝叶斯公式 1,读者发现了什么异同了没有?是的,这次民警考察将考察范围扩大了,不仅仅要考察嫌疑人(既 B),还要从部分非嫌疑人(既 ¯B)对象上来考察了,这才是贝叶斯公式 2 想要告诉我们的真谛;那么对应的因果又该如何判断呢?同样,笔者通过下面的步骤一步一步的进行详细的推导,
- 民警通过走访调查后判断 B 是坏人的可能性为 P(B),同时 ¯B 为坏人的可能性为 P(¯B),
- 然后分别以 B 和 ¯B 为判断条件,判断其谋杀 A 的可能性分别为 P(B|A) 和 P(¯B|A),
- 好了,同样,我们有了上述三个
结论( 既已知 P(B)、P(¯B) 和 P(¯B|A) ),然后我们要通过该结论来推断出到底是 B 的作案动机大还是 ¯B 的作案动机大?既是去求解出 P(B|A) 和 P(¯B|A) 的概率分别是多少;
从试验的角度而言,能够通过人类的实验或者经验判断出来的我们视为结果,所以 P(B)、P(A|B)、P(¯B) 和 P(A|¯B) 是实际能够得到的结果,而贝叶斯公式 2 所存在的意义正式通过这样的结果去推断得出它的原因是什么,而被推导出来的原因既可以是 P(B|A) 也可以是 P(¯B|A),这就要看实验者的选择了,去求解哪个原因,很显然,这里我们是想得知的原因是 P(B|A);补充,正如笔者在贝叶斯公式 1 中所描述的那样,因果事件是从社会认知学中所定义的事所描述的,所以从这个角度,我们将 A 定义为结果,而将 B 定义为原因,个中原由不再赘述;
注意,从这里笔者所总结出来的是,贝叶斯公式 2 主要是去判断不同种类之间的可能性,而贝叶斯公式 1 主要的目的是去判断相同种类下不同的样本点之间的可能性,所以两者思考和判断问题的维度和粒度不同,不能混为一谈!
补充,将谋杀案的这个例子其实用在贝叶斯公式 2 上的确有点儿违背事实常理,因为通常而言,民警不太会去关注 ¯B 作案的概率,因为 ¯B 本身作案的可能就非常非常的低,所以去考察 P(¯B|A) 没有太大的实际意义,但是为了能够说清楚贝叶斯公式 2 与贝叶斯公式 1 的区别,还是用同一例子比较好,直观,形象,透彻!在下面的肝癌检测报告的例子中,就能非常明显的体现出它的价值所在了。
例子
肝癌检测报告
某地区居民的肝癌发病率为 0.0004,现用甲胎蛋白法进行普查,医学研究表明,化验结果是存有错误的。已知患有肝癌的人其化验结果 99% 呈阳性(有病),而没患肝癌的人其化验结果 99.9% 呈阴性(无病)。现某人的检查结果呈阳性,问他真的患肝癌的概率是多少?
解,
先理解题目,将该问题描述得更为详细一些,既是某人的检查报告显示它患了肝癌,但是我们知道检查报告是有误差的,试问,通过该检查报告便能断定此人患癌的可能性有多大?所以这道题目所要求解的问题是,通过一份肝癌检查报告,能够断定出真患癌症的概率是多少?这样我们便能够将对应的因果事件给定义出来了;
- 首先,试问
结果是什么?既是通过人类的实践活动所能够总结出来的经验是什么?该结果自然就是肝癌检查报告并将该事件记为 A; - 然后,由该
结果反推所能得到的原因又是什么呢?既是通过试验的结果能否推知其原因呢?根据题设,这里所要知道的便是,当某人的肝癌检查报告显示为阳性,那么此人真的患癌的可能性是多少?而真的患癌就是这里通过检查报告曾阳性(既“结果”)所要反推出来的原因,并将该表述“原因”的事件既“真的患癌”记为 B,既是要求解在 A 的条件下 B 的概率 P(B|A);
当得出因果事件以后,首先,我们来看结果 A 由哪些结论所构成,如下所示,
P(B)=0.0004,P(¯B)=0.9996,P(A|B)=0.99,P(A|¯B)=0.001
根据贝叶斯公式 2 我们有
P(B|A)=P(BA)P(A)=P(B)⋅P(A|B)P(B)⋅P(A|B)+P(¯B)⋅P(A|¯B)=0.0004×0.990.0004×0.99+0.9996×0.001=0.28375
也就得出了此人在得出癌症检测报告以后真的患上癌症的可能性仅为 28.4%,天哪噜!你会深度怀疑这个检测设备或者这种检测方法的准确性,差不多 5 份患癌检查报告中只有 1 个人能够确诊,那还要这种检测方式来干嘛呢?其实这和抽样的模型有关,关键是看抽样的样本空间 Ω 的范围,这里的某个人可能是 B 也可能是 ¯B,所以抽样的样本空间为 B∪¯B=Ω,既判断的是从该片区中的所有人群通过癌症检查报告来判断是否真的患上了肝癌;笔者将这种抽样模型通过下面的这张概念图进行描述,便可以一目了然了,

如图,左下方红色表示 B 既是患肝癌的人群,可见其只占了很少的一部分,而 A 分别与 B 和 ¯B 相交,可以知道,如果是 B 中的某个样本点去做检查,得到 A 既检查报告曾阳性的可能性非常高,大部分的 B 都会得到这样的报告,而如果是 ¯B 中的样本点去做检查,虽然可能性极低,但是因为 ¯B 的人口基数特别大(既是样本点占绝大多数),所以即便如此,得到 A 的人相对于 B 而言仍然占大多数,也就是说我们有 |B∩A|<|¯B∩A|,由此可知,Ω 中的样本点中,即便检查出来是 A,但是是真 B 的可能性并不高,这也就解释了为什么某人在 Ω 样本空间的情况下,即便是检查出来癌症报告曾阳性,但是是真患肝癌的可能性却如此的低了;有意思的是 P(¯B|A) 又是多少呢?既是说,在有结果 A 的前提下,得到原因为 ¯B 的可能性又是多少呢?计算出来估计又得让你吃上一惊了,
P(¯B|A)=1−P(B|A)=0.71625
也就是说,在这种抽样模型下,某人的检验报告即便曾阳性,但其不患癌的概率是接近 72%,当然,当我们求证了 P(B|A) 的情况,P(¯B|A) 的情况也就没有什么好吃惊的了。但是,现在的问题是,这种检验的方法对第一次来检测的人并且能够测验出真的患癌的可能性真的不高呀!该怎么解决呢?
- 继续提高检测的精度,让 B 既
原因能够得 A 既结果的可能性尽量为 100%,也就是说几乎没有任何的误差,精度在99.9999999%,这样检验结果在 Ω=B∩¯B 的情况下就几乎不会被 ¯B 所干扰了;但是这样做的成本巨高,除非我们的检验方式和仪器能够出现质的飞跃,因此,这个可能性在短期内是不可能实现的;那么在现有的情况下,是否有办法能够提高检测的精确性呢?答案是有的, - 复查,既是在已经被检查出来为阳性的疑似患癌的人群中进行第二次检验,这就是笔者后面要讲到的根据贝叶斯公式 1 的求解方式了。
复查,继续使用贝叶斯公式 2
这种情况下,既是在疑似患癌者人群中再去进行复查,既是以上述 A 的所有样本点做为新的样本空间 S 来进行再次检查,此时结果仍然为检查报告呈阳性的患者,将该事件记为 A′,现在根据结果来推知其原因既真的患癌的可能性是多少?这里将此真的患癌该事件记为 B′,这时,我们有
P(B′|A′)=P(B′A′)P(A′)=P(B′)⋅P(A′|B′)P(B′)⋅P(A′|B′)+P(¯B′)⋅P(A′|¯B′)
- 由于检测精度和设备并没有发生任何变化,所以有 P(A′|B′)=P(A|B)=0.99 且 P(A′|¯B′)=P(A|¯B)=0.001;
- 又因为 P(B|A)=0.28375,所以该值是 A 中(既当前的样本空间 S)中真患癌人数的比例,那么也就是说,在以 S 为新样本空间的前提下,有 P(B′)=0.28375,所以有 P(¯B′)=0.71625
将上述的结论代入上述的公式,有
P(B′|A′)=P(B′)⋅P(A′|B′)P(B′)⋅P(A′|B′)+P(¯B′)⋅P(A′|¯B′)=0.28375×0.990.28375×0.99+0.71625×0.001=0.99745为什么这次的检验成功率就这么高呢?归根结底还是因为这次的抽样模型发生了变化,我们使用了 A 的样本点集作为新的样本空间 S,而因为 A∩¯B=¯B′<<¯B,所以 S (既 A) 中没有患癌的人这次对检查结果的影响微乎其微;笔者将这种情况通过下面这张概念图进行了抽象解释,

此时,在 S 中,检查呈阳性的可能性既 A′ 的样本点在 B′ 中占了绝大多数,而在 ¯B′ 中所占的样本点只占了很小的一部分;可见,某人复查的情况正好与第一检查的情况颠倒了过来,好玩吧~~ 所以,想要提高检查的精度,在技术手段无法突破的前提下,对疑似患者直接进行复查是提高检查精度的最快速也是最有效的手段和方式。
注意
此例子主要是针对两类人群进行的概率评估,既是从真患有癌症和没有患癌的两类人的并集中抽取样本进行评估计算;并没有涉及到使用到贝叶斯公式 1 的方式,既是对同一类人的个别样点进行抽样评估,找出最优可能的样本点。
技巧
老是记不住 P(BA) 或者 P(A) 的展开式,怎么办?记住,B 是 A 的前提,就是 A 的条件事件;所以,这样在来写相关的展开是就容易多了,
➭ 乘法公式
P(BA)=P(B)P(A|B)=P(B)⋅P(BA)P(B)➭ 全概率公式
P(A)=P(B)P(A|B)+P(¯B)P(A|¯B)- 每当遇到求解 P(ABC) 这样的概率的时候,首先要映入脑海的是 Ω 是什么?假设 ABC=D,那么样本空间 Ω 就是 D 所对应的样本空间,假设 A、B、C 分别代表三个步骤,且每个步骤随机抽取得到一个事物,分别记为 α、γ 和 β,那么 Ω 就是由 α、γ 和 β 三个事物所组成的全排列空间。