前言
本文为笔者所著 Go 语言基础系列之一,本文为作者原创作品,转载请注明出处;
特性
协程是 Golang 在用户层所创建的虚拟线程,拥有自己的堆和栈;数千个协程可以共享同一个内核线程,协程之间的调度由 Go Runtime 来控制,内核线程无感知;协程之间通过管道 Channel 来通讯,避免对内存资源相互竞争(race condition);
Main Goroutine
程序执行的时候,Go 会为 Main 函数单独创建一个 Goroutine,称作 Main Goroutine 主协程,也称作 Controller;
Goroutine
- 通过关键字 go 调用一个方法即刻启动一个协程;
- 当 Main Goroutine 执行完毕以后,其他的 Coroutines 也立刻结束,无论这些 Coroutines 正在执行与否;
- 协程的返回值将会被 Controller 所忽略,也就是它的返回值在主协程中是无效的;其实这一点很显然,因为协程相对于主协程而言是异步执行的;
来看下面这个例子,
1 | package main |
在 main 方法启动的时候,Golang 会为 main 方法单独创建一个 Main Goroutine,然后,我们通过关键字go启动了一个 Goroutine;为了避免主协程直接退出,代码 22 行需要等待用户的任意输入,主协程才会结束;
Channel
协程之间是通过管道 Channel 进行通讯的;通常情况下,为了避免多个线程对同一内存资源竞争(race condition),通常,我们是通过对该公共资源上读写锁来实现的,原理虽然简单,但是在代码实现过程中往往变得晦涩难懂;因此,有人提出使用消息传递机制来避免使用大量的读写锁来避免竞争,这种机制的原理其实很简单,就是得到消息的线程才有权访问(修改)此资源,当访问完毕,再将状态通过消息发送给另外一个线程,这样,该线程又获得了对该资源的访问权限,而它在代码中的逻辑也非常简单,清晰易懂;消息传递机制英文称作 Communicating Sequential Processes,由 C. A. R. Hoare 很早以期就提出了;
创建
- 声明
通过关键字chan T声明一个管道,T表示类型; 创建
两种方式可以创建一个管道,一种方式,先声明后创建,
1
2
3
4
5
6
7
8
9
10
11
12package main
import "fmt"
func main() {
var a chan int
if a == nil {
fmt.Println("channel a is nil, going to define it")
a = make(chan int)
fmt.Printf("Type of a is %T", a)
}
}代码第 6 行首先声明了一个
int类型的管道a,这个时候 a 的值为nil,表示未初始化;另一种方式就是直接创建,
1
a := make(chan int)
声明和初始化一并完成;
收发消息
语法
1 | data := <- a // read from channel a |
a 表示一个已经初始化好的管道,
data := <- a表示从管道a中读取,将读取到的值存放到变量data中;a <- data表示将变量data中的值写入管道a中去,也就是通过管道a将消息发送出去;
阻塞
设某协程中有一管道 C,
- 当该协程使用 C 发送数据后,该协程将会一直被阻塞,直到接收方
读取到数据; - 当该协程使用 C 开始接收消息后,该协程将会一直被阻塞直到发送方
写入数据;
来看一个例子,
1 | package main |
代码第 13 行开启了一个协程,但是,这段代码并没有像预期那样,打印出 Hello world goroutine ,而是直接输出了 main function;其实这个结果是显而易见的,因为主协程(Main Goroutine)不会等待 hello 协程,它会直接退出,因此导致 hello 协程没有执行完,整个程序便结束了;这里,我们可以利用管道阻塞的特性,达到我们预期的目的,让主协程等待 hello 协程执行完后才退出,代码如下,
1 | package main |
代码第 15 行,主协程开始接收管道 done 的消息,它会一直阻塞直到发送方发送数据,也就是等待 hello 协程往管道 done 写入数据,而这个步骤正好就是 hello 协程的最后一步,因此,再次执行,我们将会得到我们所预期的结果,
1 | Hello world goroutine |
死锁
例子
看官文的描述,
A deadlock happens when a group of goroutines are waiting for each other and none of them is able to proceed.
当所有的协程都在相互等待的时候,且没有一个协程可以继续执行的时候,死锁便产生了;看一个例子,
1 | package main |
Go runtime 提示出错,
1 | fatal error: all goroutines are asleep - deadlock! |
fatal error: all goroutines are asleep - deadlock!;代码很简单,也很明显,这是一个死锁,因为没有任何一个 Goroutine 能够消费;
Go runtime 是如何检测到死锁的
要注意的是,这是一个 runtime error,也就是说,在程序执行期间,由 Go runtime 检测出来的;笔者好奇的是,Go 是如何检测到死锁的?看官文的描述,
Currently Go only detects when the program as a whole freezes, not when a subset of goroutines get stuck.
也很简单,Go 只是去检查整个程序(所有的 Goroutines)是否都已经停止了,如果是,那么就是发生了灾难,Deadlock;很显然,上面这个例子只有一个 Main Goroutine,而它将会永远被阻塞,因此,Go runtime 检测到,整个程序已经被阻塞停止了,因此抛出 Panic Deadlock 异常!
谁优谁劣
With channels it’s often easy to figure out what caused a deadlock. Programs that make heavy use of mutexes can, on the other hand, be notoriously difficult to debug.
上面这段官文的意思就是说,由管道所引起的死锁,通常都非常容易排查;但是如果是因为锁引起的,那么,排查问题的原因将会是非常艰难的!所以,即便管道也会产生死锁,但相比之下,它明显比用锁来避免 race condition 更为优秀;在后面笔者会介绍如何用 Channel 来实现互斥!
Reference
https://yourbasic.org/golang/detect-deadlock/
单向管道
故名思议,单向管道就是指该管道要么只能收,要么只能发,消息;但是,很明显,谁会往一个不能读取的管道中去写入数据呢?写入的数据谁来接收呢?这不是矛盾的且不合理的吗?其实 Golang 所设计的单向管道的目的在于,在某些特殊的方法中,我们为了限制管道的用法,将一个双向管道强制转换为一个特定的单向管道,让它在该方法中要么只能读,要么只能写,仅此而已;也就是说通常,单向管道是由双向管道强制转换而来的,当然,你也可以不从双向管道转换而来,而是直接创建一个单向管道,如下,
语法
chan<- T创建一个只能发送的管道,1
sendch := make(chan<- int)
这里,我们直接创建了一个只能发送的管道;
- 语法
<-chan T创建一个只能接收/读取的管道
来看一个例子,
1 | package main |
代码第 10 行,创建了一个只允许写入的管道 sendch;运行,报错 main.go:12: invalid operation: <-sendch (receive from send-only type chan<- int),代码第 12 行报错,很显然,这里不能对一个只能写入的管道进行读取,因此报错;其实,正确的用法如下,
1 | package main |
代码第 10 行,这次,一开始,我们创建的是一个双向管道 chnl,只是,在主协程调用方法 sendData 中将入参 chnl 强制转换成了一个只写管道 sendch;执行,输入结果 10;这才是 Golang 定义单向管道的真正用意所在;
关闭
- 使用内置方法
close(chan)来关闭一个管道; - 我们依然可以读取一个被关闭的管道,只是这个时候,我们读取到的永远是
0; 使用语句
1
v, ok := <- ch
通过返回的状态值
ok来判断一个管道是否已经关闭,若ok==true,则表示该管道 ch 已经关闭;
来看一个例子,
1 | package main |
协程 producer 通过循环将数字写入 chnl 管道,注意,当写完 10 个数字以后,代码第 11 行,将管道关闭了;这个时候,代码第 18 行,主协程通过状态值 ok 来判断管道是否已经关闭,如果已经关闭,则跳出该无限 for 循环;
不过上述的例子中,我还有一个疑惑,那就是如果 producer 要比 consumer 快,consumer 消费要慢许多,那么势必导致,在 consumer 还没有完全消费完队列中的元素之前,producer 就已经调用了 close 方法,关闭了管道,那么,这个时候,consumer 是否还能够继续正常消费队列中所剩余的元素呢?答案已经在 close 方法源码的注解里了,如下,
// The close built-in function closes a channel, which must be either
// bidirectional or send-only. It should be executed only by the sender,
// never the receiver, and has the effect of shutting down the channel after
// the last sent value is received. After the last value has been received
// from a closed channel c, any receive from c will succeed without
// blocking, returning the zero value for the channel element. The form
// x, ok := <-c
// will also set ok to false for a closed channel.
has the effect of shutting down the channel after the last sent value is received,close 方法会在最后一个已发送的元素被消费后,才会关闭队列,因此,这个顾虑是不存在的!
循环读取
上一个小节所介绍的循环读取某个管道中数据的例子,循环语句稍显复杂;Golang 提供了一组关键字 for range 来简化该操作;例子如下,
1 | package main |
我们将上一小节无限 for 循环的判断语句改写成了一行代码 for v := range ch,它会自动检测管道 ch 是否已经关闭,若已经关闭,将会自动退出该 for 循环;
Buffered Channel
创建
1 | ch := make(chan type, capacity) |
- 参数 capacity 表示需要创建多大容量的缓存管道;
带有缓存的管道可以理解为一个 FIFO 的队列;并且,当有多个协程同时消费一个带缓存的管道的时候,它是线程安全的,
阻塞
我们知道,普通的没有缓存的 Channel,每发送一条数据后,相关的协程立刻便会被阻塞;而有缓存的管道(Buffered Channel)的性质是,假设我们有一个带缓存的管道 BC
- 某个协程往 BC 中不断的写入数据的时候,当 BC 被写满后,该协程将会被阻塞,直到 BC 中有新的空位被腾出;
- 某个协程从 BC 中不断的读取数据的时候,当 BC 被取空后,该协程将会被阻塞,直到 BC 中有新的数据被写入;
来看一个例子,
1 | package main |
上面这个例子,produce 协程将会在写入人名 kane 第地方阻塞,也就是阻塞在代码的第 13 行,运行代码,输出结果,
1 | produced naveen |
很明显,因为 consume 协程迟迟不消费,导致 produce 协程已经把管道 ch 写满了,导致 produce 协程阻塞了;
死锁
由上一个小节死锁中,我们知道,Go runtime 在执行过程中,若发现所有的 Goroutines 都相互阻塞了,那么就会抛出运行时刻的 fatal errors,Dead lock;下面我们来看一个由 Buffered Channel 所导致的死锁的例子,
1 | package main |
运行,代码在执行到第 13 的时候,抛出 Dead lock 的运行时异常;Buffered Channel 的容量为 2,当写入 paul 以后,该 channel 便被阻塞了,且当前只有一个 main goroutine,所以,Go runtime 检测到整个系统已经停止了,便立即抛出了 Dead lock 异常;
Length vs Capacity
- Length
表示 channel 中当前可用的元素的长度; - Capacity
表示 channel 总共的容量;
WaitGroup
这个关键字 WaitGroup 的名字取得非常的形象,直译过来表示“等待一组东西”;WaitGroup 的目的在于让当前的 goroutine A 等待,直到它所监控的其它 goroutines 都执行完成以后,才唤醒 A 让它继续执行;可以形象的想象为,有个水闸,只有等待所有的水都满了以后,才会开闸放水;笔者联想到了 Java 线程中的 Latch,门栓,只有等待所有被监控的 Java 线程执行完以后,这个门栓才会被打开;来看一个例子,
1 | package main |
- 代码第 23 行,对主协程上锁,让它等待,这步很重要,避免主协程直接退出;
- 代码第 20 行,通过
wg.Add(1)给 WaitGroup 计数 +1,表示该线程目前已被 WaitGroup 所监控; - 代码第第 13 行,通过
wg.Done()给 WaitGroup 计数 −1,告诉它,某个被监控的协程已经执行完毕; - 直到所有被 WaitGroup 监控的协程都执行完毕后,wg.Wait() 开始放行,允许主协程继续执行;其实也就是当 WaitGroup 实例 wg 的计数等于 0 以后,放行;
WaitGroup 的实现原理非常简单,它维护一个计数器,当某个或多个协程需要被监控的时候,通过 WaitGroup.Add(n) 方法将计数器 +n,表示当前有 n 个协程已经在它的监控中了;当某个被监控的协程执行完毕后,通过 WaitGroup.Done() 使得计数器 −1,并且直到 WaitGroup 中的计数器为 0 的时候,则立刻放行被 WaitGroup 所阻塞的 Goroutine;
Worker Pools
Worker Pools、Goroutine Pools、Thread Pools 在 Golang 中都表示同一个意思,实际上就是协程池;
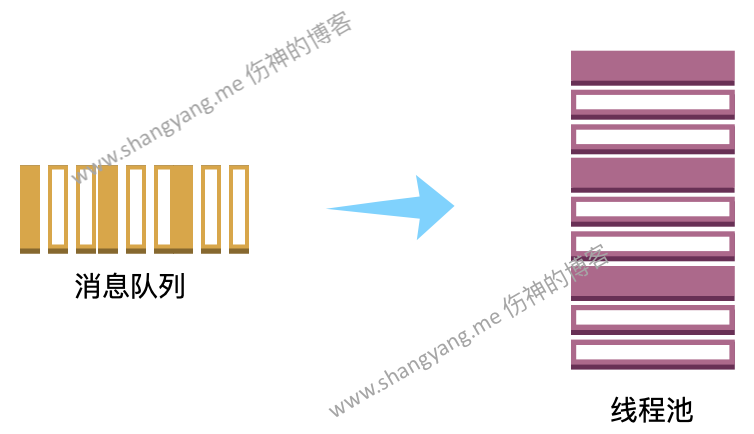
通常,完整的线程池通常由两部分组成,消息队列和线程池;Golang 中,自然,线程池由协程池构建,消息队列自然就是上面所提到的管道 Channel;消息队列用来提供需要被处理的源数据,协程池来处理这些数据,要注意的是,协程池中的多个协程将会同时并发访问该消息队列也就是管道 Channel,因此,Golang 在设计上,管道必须是线程安全的;
下面,来看一个非常简单的 Worker Pools 的例子,这个例子中,worker pools 中的 workers 将会并发消费消息队列 jobs 中的任务;
1 | package main |
- 代码第 19-20 行,初始化了管道 jobs 和用来存放计算结果的管道 results;这里的 jobs 管道充当
消息队列由 Worker Pool 中的 Workers 并发访问; - 代码第 73 行,逐步生成有 100 个 jobs 消息的管道既生成了消息队列;
- 代码第 77 行,创建 Workers,构成 Worker Pool;Workers 由协程构成,因此这里最准确的表达是
协程池;要注意的是,协程池中的多个协程将会同时并发访问同一个 jobs 管道;
上面的这个例子只是非常简单的模拟了一个协程池的大致模样;真正的协程池,输入数据应该来自于网络,典型的高并发场景就是,数据来自于 socket,然后采用 I/O 多路复用的方式,将数据缓存在内存中,然后通过回调的方式直接将数据直接提供给协程池进行并发处理;另外,一般而言协程池中的协程是不应该在某个任务执行完以后就直接被销毁的,通常而言,这些协程是一直存在的,协程中所处理的任务通过接口解耦合从而实现可执行任务的多样性;
Select
Select 同时监听多个管道,然后,根据不同的策略,只会选取接收其中一个管道的结果;
优先响应
同时监听两个管道,哪个管道先返回,就获取谁的数据,另外一个管道的数据就丢弃;
假设,我们有两个同步数据源,分布在不同的地域,同时读取,自然,为了及时响应,谁先返回就取谁的数据;下面,用 server1 和 server2 模拟了这种情况,
1 | package main |
程序输出 from server2,因为 server2 优先响应;
Default case
当读取的时候,如果其他的 case 都还没有数据响应,便会立刻执行 default case,看一个例子,
1 | package main |
执行结果如下,
1 | no value received |
无限 for 循环将会每个 10 秒读取一次管道 ch,看看是否有返回值,而生产者 process 要 10.5 秒之后才能产生数,因此,头 10 次读取,process case 并没有准备好,打印 default case 的结果,no value received,知道 10 次以后,才输出 process case 的返回结果;
可用来处理业务数据响应超时的情况,
Default case 还经常用在管道数据响应超时的情况,想想,如果通过管道返回一个数据库查询的结果,但是管道 10 分钟了都迟迟没有返回结果?那么可以使用 Default case 来处理这种响应超时的业务异常;
随机选择
当几个管道同时返回结果的时候,Select 将会随机选择一个返回值;例如,
1 | package main |
管道 output1 和 output2 同时返回数据,这个时候,Select 将会随机的执行 case s1 或者 case s2;多执行上述代码几次,将会分别随机的打印出 from server1 和 from server2;
Empty select
1 | package main |
一个空的 select 表示没有任何的 case,这个时候,主协程将会一直被阻塞,知道 runtime error, deadlock!
1 | fatal error: all goroutines are asleep - deadlock! |
Mutex
Mutex 在多线程的竞态条件(Race Condition)下,给共享的公共资源加锁,保证数据的一致性;
发生竞态条件
下面来看一个竞态条件下,数据一致性被破坏的例子,
1 | package main |
我们期望最终结果输出为 1000,但是,每次执行,得到的结果不同且都小于 1000;因为公共资源 x 被多个协程同时并发访问,导致 x 的数据一致性被破坏 - 这就是我们常说的某个公共资源存在竞态条件既 race codition;
通过 Mutex 解决竞态条件
还是以上面的这个例子为例,我们如何解决对于公共资源 x 的竞态条件呢?核心步骤很简单,既是在对公共资源 x 进行写操作的时候,通过 Mutex 上锁即可,
1 | mutex.Lock() |
mutex.Lock()表示当前协程对接下来的程序片段的入口上锁,当其它协程同时执行到此处,便会被阻塞,强制等待,直到当前协程释放锁,才能允许访问,注意,这个时候,同样只有一个协程能够获得锁的权限,其它协程继续等待;这样,就能保证互斥的修改存在竞态条件的公共资源 x 了;下面来看完整的例子,
1 | package main |
在写公共资源 x 的时候通过 Mutex 上锁,这样便保证了 x 的数据一致性;
通过 Channel 解决竞态条件
1 | package main |
上面代码的核心思想是,通过创建一个容量为 1 的带缓存管道,为具有竞态条件的资源 x 上锁;代码第 10 行,当某一个协程 α 为管道ch赋值以后,ch 便无法再被赋值,因此其它协程在此处被阻塞,直到代码第 12 行协程 α 将 ch 的值取出为止,这个时候,ch 允许写入,众多等待的协程将会有一个幸运儿获得对 x 的锁;这样,我们便通过管道实现了对 x 的互斥访问;
谁优谁劣
通常而言,如果只有一类协程需要并发访问互斥资源 x,那么用 Mutex 简单高效,就像上面这个例子那样,只有 increment 协程需要并发访问互斥资源 x,因此使用 Mutex 更为合适;但是如果多个不同的协程之间,不但需要互斥访问资源 x,而且还需要相互通讯的时候,这种情况下使用管道来实现互斥,代码逻辑更为简单,来看下面这个例子,
1 | package main |
上面这段代码先通过 increment 协程对 x 加 1,然后通过管道 data 将中间结果传递给 decrement 协程,然后 decrement 对 x 减 2,因为 x 是存在竞态条件的,因此要求整个对互斥资源 x 的访问过程都是互斥的,因此,需要同时对 increment 和 decrement 协程中访问 x 的地方上锁;更准确的说,是在 increment 协程中对 x 进行上锁,在 decrement 协程中对 x 释放锁;上面这段代码执行后,我们得到了期望值 -1000,可见,在上述由两个协程所构成的多线程的环境下,对互斥资源 x 的访问过程中是线程安全的,不过,其实这里的两个管道 mutexch 和 data 都起到了对 x 的互斥保护的作用,mutexch 锁的粒度更大,它的锁粒度是横跨了两个协程,主要限定了对 x 资源访问的开始和结束的边界,而 data 管道主要保证 decrement 协程对 x 的互斥访问,它会阻塞 decrement 协程直到 increment 将中间结果传递过来;
综上,Mutex 适合简单的情况,也就是只有一种协程的情况;而管道非常适合复杂情况下的互斥访问,尤其某个互斥资源需要在多个协程之间进行先后协作访问的时候,想想,如果上面的这个例子通过 Mutex 的方式来实现,得需要多少个锁,多少种情况需要考虑?即便是实现出来了,代码也必然也是晦涩难懂不易于维护的!如果可以,笔者个人认为,尽量使用管道实现互斥更佳!