前言
打算写一系列文章来记录自己学习 Python 3 的点滴;
Thread Pool
类图以及主要元素
Python3 在 concurrent.futures 包中提供了 Python 的 Thread Pool 的功能;主要有如下的对象所构成,
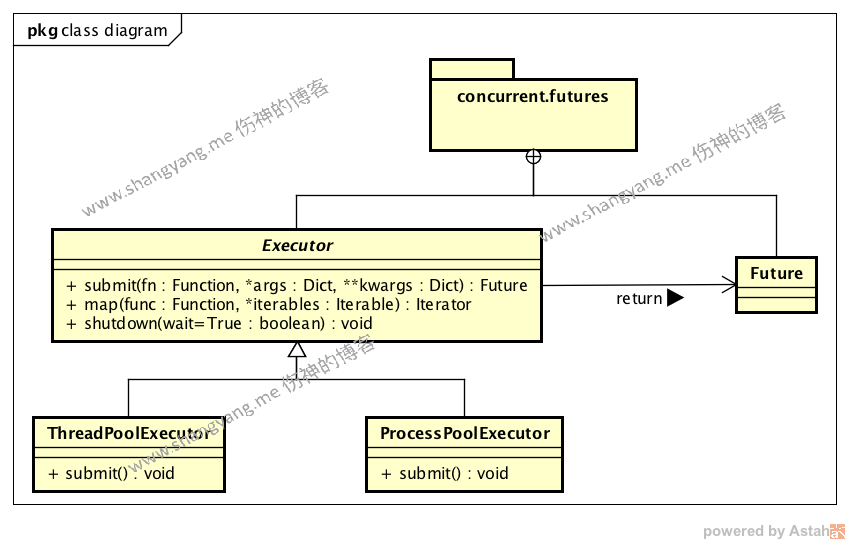
Executor
这是一个抽象类,定义了线程异步执行的内部实现逻辑,核心方法- submit
这一步提交一个任务,Executor 负责以异步的方式执行既以线程的方式执行,并且返回一个 Future 对象,封装了异步线程的执行等待逻辑以及返回结果; - map
TODO shutdown
关闭 Executor 并释放其所有资源;但是,有个前提,就是必须等待所有已经 submit 过的线程都执行完毕以后(且不管该线程现在是否在等待中、或者已经开始执行),才释放资源;如果对一个已经 shutdown 的 Executor 对象进行 submit 或者 map 调用,将会抛出 Runtime Error;接收参数 wait- wait=True
阻塞主进程,等待并直到所有线程都执行完毕以后,返回并释放所有资源; - wait=False
不阻塞主进程,立刻返回,但是 Executor 依然要等待所有的线程执行完毕以后,才释放资源;
具体实例,参考 shutdown 示例
- wait=True
- submit
- Future
Executor.submit() 方法返回一个 Future 对象,该对象负责实现异步执行等待逻辑,以及执行结束以后,将执行的结果进行封装并返回; - ThreadPoolExecutor
该对象继承自 Executor,主要是提供了线程池的能力,通过 ThreadPoolExecutor 中的 thread worker 对象,我们能够严格控制当前执行的线程数量,并且通过线程池,我们可以缓存将要执行的线程,实现了待执行线程队列的能力; - ProcessPoolExecutor
TODO
Future
1 | with ThreadPoolExecutor(max_workers=1) as executor: |
- executor.submit() 方法将会向 thread pool 中提交一个待执行的任务,若,当前有空闲的 worker,那么该任务将会被立即执行;
- executor.submit() 将会立即返回一个 Future 对象,该对象封装了异步线程的执行等待逻辑,并且,当线程的异步操作执行完成以后,返回该线程执行的结果;
future.result() 的行为类似于 thread.join() 操作,会一直阻塞主进程直到结果返回为止;所以,如果我们同时有多个 Future 对象,那么像上面这种写法,等待前一个 Future 对象的时候会阻塞后续的 Future 对象,比如,
1
2
3
4
5with ThreadPoolExecutor(max_workers=1) as executor:
future1 = executor.submit( do something really long )
future2 = executor.submit( do something really short )
print(future1.result())
print(future2.result())任务短的 Future2 会一直被阻塞;那么该如何解决呢?后面笔者会通过实例来讲解;
重要的方法
- add_done_callback(fn)
fn 是在当 future 执行完成时的回调方法,fn 接受唯一一个 future 对象作为自己的参数,并且,该回调方法 fn 是在该 future 所对应的线程中执行的;
ThreadPoolExecutor
ThreadPoolExecutor 继承自 Executor 并提供了线程池的能力,看下面这个例子,
1 | import concurrent.futures |
注意上面的代码第 19 行,1
for future in concurrent.futures.as_completed(future_to_url)
concurrent.futures.as_completed({Future1: val1, Future2, val2…}) 通过检测 Futures 中是否有任意一个 Future 执行成功,如果有任意一个执行成功则返回;注意,这里,并不会像 Future.result() 那么样阻塞主进程,因为它只是简单的判断一下 Future 是否完成,便立刻返回,直到某个 Future 完成以后才会输出;来简单看看 concurrent.futures.as_completed 的源码,1
2
3
4
5
6
7
8
9
10
11
12while pending:
...
with waiter.lock:
finished = waiter.finished_futures
waiter.finished_futures = []
waiter.event.clear()
for future in finished:
yield future
pending.remove(future)
只要有任何一个线程处于 pending 状态,while 循环都不会退出,代码 5 ~ 8 行,就是简单的判断是否有线程执行完毕,若完毕,则会通过第 10 行的 for 循环通过 yield 命令将该 future 返回;所以,这里它并不会阻塞后面的 Future;来看看其返回的结果,1
2
3
4
5> 'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 8] nodename nor servname provided, or not known>
> 'http://www.foxnews.com/' page is 227219 bytes
> 'http://www.cnn.com/' generated an exception: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
> 'http://www.bbc.co.uk/' generated an exception: Remote end closed connection without response
> 'http://europe.wsj.com/' generated an exception: <urlopen error timed out>
嗯,上面大部分网站都被墙了,不过没关系,可以看到,它并非是按照 URLS 中的 URL 所创建的 Future 对象的顺序进行返回的,而是,谁先执行完成便返回,所以,获取后一个 Future 对象的结果并不会被前一个 Future 对象所阻塞;但是依然会阻塞主进程;但是对于大多数异步执行的 Job 而言,足够了;最完整的异步编程框架,还是 Python 的 Twisted 和 Node.js 的 Event Loop 框架做得彻底,整个异步编程的过程以及结果的返回都不会阻塞主进程,要想普通单机能够支持 10W 级以上的并发,非这两个框架莫属不可;
shutdown 示例
依然使用 ThreadPoolExecutor 中的例子,但是这里稍作如下修改,
- 将 max_workers 的数量设置为 2
- 当所有资源都 submit 以后,立刻 shutdown executor
这样,同一时间只有 2 个线程在执行,必然有 3 个任务在等待,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
executor.shutdown(wait=False)
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
执行结果如下,1
2
3
4
5'http://www.bbc.co.uk/' generated an exception: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
'http://some-made-up-domain.com/' generated an exception: HTTP Error 403: Forbidden
'http://europe.wsj.com/' generated an exception: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
'http://www.cnn.com/' generated an exception: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
'http://www.foxnews.com/' page is 233220 bytes
可以看到,即便我在上面的代码第 19 行调用方法 shutdown 立刻关闭了 executor,但是 5 个已经 submit 的线程依然正常执行,并且等待所有资源都执行结束以后,executor 才会释放掉相关的资源;第 19 行代码可以修改为,1
executor.shutdown(wait=True)
这样,主进程将会一直阻塞,直到所有线程执行完毕以后,才返回;
References
https://docs.python.org/3/library/concurrent.futures.html
https://pymotw.com/3/concurrent.futures/