概述
Linux 系统的虚拟网络设备的目的就是在操作系统层面去模拟现实中的交换机,网卡等以及他们之间的通讯方式,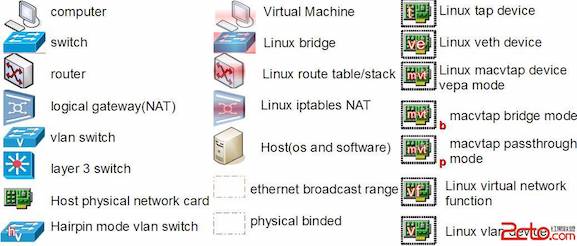
- 图中左列为现实世界中的物理设备
- 电脑终端
- 二层交换机
- 路由器
- 网关
- 支持 802.1Q VLAN 的交换机
- 三层交换机
- 物理网卡
- 支持 Hairpin 模式的交换机
- 图中中列为虚拟机中的元素
- 虚拟机
- Linux Bridge
- Linux 路由表
- Linux iptables
- Host 主机
- 棕色虚线框表示以太网广播域
- 黑色虚线框表示物理捆绑关系
- 图中右列为 Linux 系统里的网络设备
- TAP 设备
- VETH 设备
- 工作在 VEPA 模式的 MACVLAN 设备
- 工作在 Bridge 模式的 MACVLAN 设备
- 工作在 Passthrough 模式的 MACVLAN 设备
- SRIOV 的虚拟 VF 设备、VLAN 设备
- Bridge 设备(补充,图中没有画出)
关于 Linux 系统里的网络设备补充一点,通过安装扩展 bridge-utils 包,可以在 Linux 系统中模拟生成虚拟交换机。
Linux 上的虚拟网络设备
virtual bridge
安装
Ubuntu1
$ apt-get install bridge-utils
与物理交换机的区别
Linux 虚拟交换机与物理物理交换机(二层)有几个区别,如下,
虚拟交换机有虚拟 MAC 地址,可以设置 IP;
也就是说,可以当做网络层(第三层)设备使用,可以收发 IP 包。说得直白一点,就是可以当做一张网卡看待;添加一个虚拟交换机,
1
2
3
4
5
6
7
8mac@ubuntu:~$ sudo brctl addbr br0
mac@ubuntu:~$ ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:53:54:23 brd ff:ff:ff:ff:ff:ff
3: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f6:e8:bc:04:8f:33 brd ff:ff:ff:ff:ff:ff设置虚拟交换机 IP
1
2mac@ubuntu:~$ sudo ip addr add 10.0.0.2 dev br0
mac@ubuntu:~$ sudo ip link set br0 up测试虚拟交换机可以接收 IP 包
1
2
3
4
5mac@ubuntu:~$ ping -w3 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.036 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.044 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=0.035 ms可见,的确如此,虚拟交换机 Bridge 的确可以看做是一个三层网络设备,可以视为一个带路由的网卡。
限制,就是当一个设备一旦被连接到该 Bridge 上以后,虽然该设备的 IP 依然存在,但是该设备的 IP 地址就会变得无效,该设备也就无法在网络层进行收发数据了;
如果在本机上 ping,依然可以 ping 通该设备,
比如,我们有网卡接口 enp0s3,地址 10.0.2.151
2
3
4
5
6
7
8
9
10
11
12
13mac@ubuntu:~$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:53:54:23 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe53:5423/64 scope link
valid_lft forever preferred_lft forever将 enp0s3 加入 br0
1
2
3
4mac@ubuntu:~$ sudo brctl addif br0 enp0s3
mac@ubuntu:~$ brctl show
bridge name bridge id STP enabled interfaces
br0 8000.080027535423 no enp0s3在本机上直接 ping enp0s3 可以 ping 通
1
2
3
4mac@ubuntu:~$ ping 10.0.2.15
PING 10.0.2.15 (10.0.2.15) 56(84) bytes of data.
64 bytes from 10.0.2.15: icmp_seq=1 ttl=64 time=0.027 ms
64 bytes from 10.0.2.15: icmp_seq=2 ttl=64 time=0.036 ms说明该限制只是在
不同主机间通讯才会导致从另外一台主机上 ping 该主机上被桥接的网卡接口,不再 ping 通
测试环境 1:虚拟机模拟另外一台主机
mac 主机与 VirtualBox 虚拟机之间通过桥接 mac 主机的物理网卡 en0 与虚拟机的网卡 enp0s8 进行通讯,
在虚拟集中,将enp0s8192.168.56.11 加入 br01
$ sudo brctl addif br0 enp0s8
结果直接导致,mac 主机顿时无法连接虚拟机,无法连接被桥接后的
enp0s81
2
3
4bogon:Architect mac$ ping 192.168.56.11
PING 192.168.56.11 (192.168.56.11): 56 data bytes
Request timeout for icmp_seq 0
Request timeout for icmp_seq 1测试环境 2:使用 network namespace 模拟另外一个主机
创建一对 VETH v0, v1,创建 namespace ns1,将 v1 纳入 ns1,当 v0 加入 br0 以后,v1 无法在网络层连接 v0。下面我们就来模拟这种情况,初始化 ns1, v0, v1,将 v1 纳入 ns1,设置相关 IP 并启动,1
2
3
4
5
6mac@ubuntu:~$ sudo ip link add v0 type veth peer name v1
mac@ubuntu:~$ sudo ip netns add ns1
mac@ubuntu:~$ sudo ip link set v1 netns ns1
mac@ubuntu:~$ sudo ip netns exec ns1 ifconfig lo up
mac@ubuntu:~$ sudo ip netns exec ns1 ifconfig v1 192.168.32.6 up
mac@ubuntu:~$ sudo ifconfig v0 192.168.32.5 up此时,在 ns1 中是可以通过 v1 ping 通 v0 的
1
2
3
4mac@ubuntu:~$ ping 192.168.32.5
PING 192.168.32.5 (192.168.32.5) 56(84) bytes of data.
64 bytes from 192.168.32.5: icmp_seq=1 ttl=64 time=0.062 ms
64 bytes from 192.168.32.5: icmp_seq=2 ttl=64 time=0.035 ms此时,将 v0 加入 br0 以后呢?
1
mac@ubuntu:~$ sudo brctl addif br0 v0
此时,在 ns1 中不可以再通过 v1 ping v0 了
1
2
3
4
5mac@ubuntu:~$ sudo ip netns exec ns1 ping 192.168.32.5
PING 192.168.32.5 (192.168.32.5) 56(84) bytes of data.
^C
--- 192.168.32.5 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1020ms
此时唯一的解决办法就是,将被桥接的网卡接口的 IP 地址赋给虚拟交换机,让它来代替原来的网卡接口在网络层收发数据。
该部分重点参考Linux 上的基础网络设备详解
TAP 设备
模拟一张物理网卡,TUN 实现了一份网络协议栈,而 TAP 实现了一个字符设备驱动;整个流程是,应用程序通过 TUN 网络协议栈将数据发送至内核(相当于是将数据发送给网卡),然后内核通过 TAP 字符设备将数据从内核空间中送出给应用程序。与物理网卡的区别是,物理网卡接收的是链路层传送过来的网络数据;TUN/TAP 是接收和转发操作系统应用程序的数据。
TUN/TAP 原理
从源码级别了解tun/tap虚拟网卡
使用
安装 TUN
检测 TUN 设备是否已经安装1
2mac@ubuntu:~$ modinfo tun
modinfo: ERROR: Module tun not found.
表示,没有安装 TUN 模块,那么需要按照如下的步骤,通过重新编译内核的方式进行安装,
首先,下载源码,1
root$ apt-get install linux-source
源码包下载的默认路径默认是在 /usr/src 中;我下载下来以后的安装包linux-source-4.8.0.tar.bz2
1 | root# cd /usr/src |
按照下面的引用文章调试,始终没能成功;引用的文章的内核版本是 3.8.0 的,而我的版本是 4.8.0
如何安装 TUN 模块
关于ubuntu12.04(64位)下使用tap设备驱动问题
就上一个文章的补充,
linux下TUN/TAP虚拟网卡的使用
VLAN
Linux 虚拟 VLAN 设备是对802.1.q 交换机的模拟,通过一个母网卡模拟出多个子网卡,母设备相当于现实世界交换机的 TRUNK 端口用来连接上级网络,子设备相当于交换机的端口用来连接下级网络;举例,eth0 作为母设备创建一个 ID 为 100 的子设备 eth0.100。此时如果有程序要求从 eth0.100 发送一包数据,数据将被打上 VLAN 100 的 Tag 从 eth0 发送出去。如果 eth0 收到一包数据,VLAN Tag 是 100,数据将被转发到 eth0.100 上,并根据设置决定是否移除 VLAN Tag;如果 eth0 收到一包包含 VLAN Tag 101 的数据,其将被丢弃。上述过程隐含以下事实:对于寄主 Linux 系统来说,母设备只能用来收数据,子设备只能用来发送数据。
与真实的 802.1.q 交换机的区别,
- Linux VLAN 母子设备拥有相同的 MAC 地址,既是母设备的 MAC 地址;
- 因为 #1 的限制,导致一个 VLANID 只能对应唯一的一个虚拟子设备;真实的交换机 802.1.q 中,同一个 VLANID 用来划分一个子网,可以有多个主机;
- 因为 #2 的原因,linux VLAN 也就不存在逻辑子网的概念或者说一个逻辑子网对应一个子设备。
更多描述参考,Linux 上的基础网络设备详解
MACVLAN
图解几个与Linux网络虚拟化相关的虚拟网卡-VETH/MACVLAN/MACVTAP/IPVLAN
VETH 设备
生成一对虚拟网卡,假设为 veth0 和 veth1,特点是,当数据流从网卡 veth0 中输入,就会从另一个网卡 veth1 中输出,应用程序可以监听 veth1 读取该数据流;其实,更形象的比喻,两者好比一条双绞线的两端直接连接两台主机,使其通讯;注意,要能够通过 IP 包访问两者,注意,两者的 IP 地址必须在同一个网段中,否则两者不能访问对方,比如 ping。
如图,我们来实现这样一个例子,从 NameSpace 1 中是如何通过 veth1、veth0 以及 eth0 访问外网。其整体思路是,通过 VETH 建立 NameSpace 1 和 Host 之间的连接通路,再通过 ip forward 将数据从 veth0 发送到物理网卡 eth0,再由 eth0 将数据包送出;另外,要保证数据包能够成功送出以及接受,必须在 iptables 中配置相关的 NAT 规则。
创建 veth pair 和 namespace,并使得通过 veth1 和 veth0 可以互
ping( veth1 属于 namespace 1 )1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 创建 VETH PAIR
mac@ubuntu:~$ sudo ip link add veth0 type veth peer name veth1
# 创建 namespace 1
mac@ubuntu:~$ sudo ip netns add ns1
# 将 veth1 加入 namespace 1
mac@ubuntu:~$ sudo ip link set veth1 netns ns1
# 设置 veth0 ip 并将其激活,设置 IP 的时候,最好加上 mask 值
mac@ubuntu:~$ sudo ip addr set 192.168.78.2/32 dev veth0
mac@ubuntu:~$ sudo ip link set veth0 up
# 激活 namespace1 lo 的环回接口
mac@ubuntu:~$ sudo ip netns exec ns1 ifconfig lo up
# 设置 namespace1/veth1 接口 IP 并将其激活
mac@ubuntu:~$ sudo ip netns exec ns1 ifconfig veth1 192.168.78.3/32 up一旦激活以后,namespace ns1 中将会生成如下的默认路由信息
1
2
3
4mac@ubuntu:~$ sudo ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.78.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1从 ns1 中通过 Interface veth1
pingveth01
2
3
4mac@ubuntu:~$ sudo ip netns exec ns1 ping 192.168.78.2
PING 192.168.78.2 (192.168.78.2) 56(84) bytes of data.
64 bytes from 192.168.78.2: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from 192.168.78.2: icmp_seq=2 ttl=64 time=0.042 ms同样,宿主机也可以
pingveth11
2
3
4
5mac@ubuntu:~$ ping 192.168.78.3
PING 192.168.78.3 (192.168.78.3) 56(84) bytes of data.
64 bytes from 192.168.78.3: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from 192.168.78.3: icmp_seq=2 ttl=64 time=0.042 ms
64 bytes from 192.168.78.3: icmp_seq=3 ttl=64 time=0.040 ms至此,该步骤的测试成功。
下面记录曾经配置的时候,遇到的
错误情况,不能 ping 通的情况,当时是将 veth0 配置成 10.111.10.2,veth1 配置成 10.111.10.3,结果不能 ping 通,大致情况描述如下,1
2
3
4
5mac@ubuntu:~$ sudo ip netns exec ns1 ping 10.111.10.2
PING 10.111.10.2 (10.111.10.2) 56(84) bytes of data.
From 10.111.10.3 icmp_seq=1 Destination Host Unreachable
From 10.111.10.3 icmp_seq=2 Destination Host Unreachable
From 10.111.10.3 icmp_seq=3 Destination Host Unreachable1
2
3
4mac@ubuntu:~$ sudo ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 veth1发现路由异常,没有 destination 10.111.10.0 的路由信息,所以需要手动设置路由信息,(后续发现问题所在,是因为在给 VETH1 设置 IP 的时候没有设置 NETMASK 的值,系统默认设置成了/8,所以这里默认生成 255.0.0.0,而不明白的是,系统给 VETH0 默认生成了 255.255.255.255,最终导致两者不能通讯 )
于是手动添加路由信息如下,1
2
3
4
5
6mac@ubuntu:~$ sudo ip netns exec ns1 route add -net 10.111.10.0/24 veth1
mac@ubuntu:~$ sudo ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 veth1
10.111.10.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1veth1
pingveth0 成功1
2
3
4
5mac@ubuntu:~$ ping 10.111.10.2
PING 10.111.10.2 (10.111.10.2) 56(84) bytes of data.
64 bytes from 10.111.10.2: icmp_seq=1 ttl=64 time=0.057 ms
64 bytes from 10.111.10.2: icmp_seq=2 ttl=64 time=0.035 ms
^C正常情况下,在 namespace 1 中激活 veth1 的时候,会写一条这样的路由;但为了避免出现异常,最好手动检查并添加
经验和教训,很多时候,不能从 veth1pingveth0 的原因,
1) 可能是 ns1 中的 route 信息没有设置正确
2) 如果 route 信息设置正确了,那么有可能是子网掩码设置出错,若一方的子网掩码设置成了 32 既是 255.255.255.255,那么是不能 ping 的,最好是保证双发 IP 的子网掩码相同,否则可能会因为子网掩码的不同,而不再同一个网段,导致不能通讯。(之前,我就犯了这个错误!)从 ns1 中
ping通物理接口 eth0
添加 ns1 的默认路由到接口 veth0 (也就是在 ns1 中添加默认路由表),这样就可以 ping 通宿主机的物理接口 eth0;
(补充,我本地 Ubuntu 虚拟机的虚拟物理接口的名称是 enp0s3, ip 地址是 10.0.2.15,但是为了契合抒写习惯,我将 eth0 定义为 enp0s3 的别名 )1
2
3
4
5
6mac@ubuntu:~$ sudo ip netns exec ns1 ip route add default via 192.168.78.2
mac@ubuntu:~$ sudo ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.78.2 0.0.0.0 UG 0 0 0 veth1
192.168.78.0 0.0.0.0 255.255.255.0 U 0 0 0 veth11
2
3
4
5mac@ubuntu:~$ sudo ip netns exec ns1 ping 10.0.2.15
PING 10.0.2.15 (10.0.2.15) 56(84) bytes of data.
64 bytes from 10.0.2.15: icmp_seq=1 ttl=64 time=0.041 ms
64 bytes from 10.0.2.15: icmp_seq=2 ttl=64 time=0.041 ms
64 bytes from 10.0.2.15: icmp_seq=3 ttl=64 time=0.041 ms开启
ip forward
通过如下命令开启,1
echo 1 > /proc/sys/net/ipv4/ip_forward
开启以后,表示同一个宿主机上的不同的网卡接口可以通过相应的路由表信息转发数据包;这里开启以后的意义在于,
举个例子,从 ns1 中通过ping www.baidu.com发出的 ICMP 数据包是如何 forward 的?
首先,我们来看宿主机的路由信息1
2
3
4
5mac@ubuntu:~$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.2.2 0.0.0.0 UG 0 0 0 enp0s3
10.0.2.0 0.0.0.0 255.255.255.0 U 0 0 0 enp0s3可以看到,有一条默认路由是添加在 enp0s3 上的,
那么,当该 ICMP 数据包从 ns1 发出,到达 veth0 后,将会通过其目的地址 www.baidu.com (61.135.169.121),寻找下一条转发的路由规则;这个时候,发现 enp0s3 的默认路由规则符合条件,于是,该 ICMP 数据包便会通过 enp0s3 接口发出,并到达网关 10.0.2.2。设置
NAT,使得从 ns1 发出的数据包的源地址在 internet 上是合法的1
mac@ubuntu:~$ sudo iptables -t nat -A POSTROUTING -s 192.168.78.0/24 ! -o veth0 -j MASQUERADE
上述配置的目的在于,但凡源地址是从
192.168.78.0/24发出的数据包,都要进行 NAT 转换,
首先,数据包的源地址将会更改为enp0s3的地址 10.0.2.15,
其次,数据包通过路由网关 10.0.2.2 的时候,会再次通过 NAT 将源地址成合法的外网地址。1
2
3
4mac@ubuntu:~$ sudo ip netns exec ns1 ping www.baidu.com
PING www.baidu.com (61.135.169.121) 56(84) bytes of data.
64 bytes from 61.135.169.121 (61.135.169.121): icmp_seq=1 ttl=61 time=42.5 ms
64 bytes from 61.135.169.121 (61.135.169.121): icmp_seq=2 ttl=61 time=45.5 ms测试成功,
疑问?通过 NAT 层层修改源地址后,数据包发送出去是可以的,但是 veth1 是如何接收到外网的反馈信息的?因为外网主机是不知道 veth1 (192.168.78.3) 存在的。这个问题其实和宿主机以及路由 session 映射相关,大致过程描述如下,
第一次 NAT,维护第一层
session映射关系
当 ns1 发起ping命令以后,会在 ns1 中随机开启一个端口,比如 66666,
通过第一次 NAT 以后,宿主机会通过session维护这样一层宿主机与 ns1 的关系192.168.78.3:66666<->10.0.2.15:77777的关系,可见,宿主机会随机开启一个端口来与 ns1 做映射。
补充,docker 在 filter 表中额外添加了如下的规则,
1
iptables -t filter -A FORWARD -o v0 -m conntrack –ctstate RELATED,ESTABLISHED -j ACCEPT
上面的配置的意思表示,就表示要维护上面所描述的这样一种 session 关系;但是,我在 Ubuntu 16.10 版本中实际的测试过程中,并没有配置该项,看来,现在应该是默认行为了。
第二次 NAT,维护第二层
session映射关系
当数据包通过宿主机经过路由器以后,路由器会通过其 session 维持这样一种关系10.0.2.15:77777<->10.0.2.2:88888
映射关系有了,那么外网主机反馈信息到 ns1 的过程如下,假设路由器(10.0.2.2)的 WAN 口地址为 172.188.98.7
- 首先,外网主机将通过路由器的 WAN 口地址 172.188.98.7 反馈给路由器
- 然后,路由器通过 session 映射
10.0.2.15:77777<->10.0.2.2:88888将数据发送给 10.0.2.15,既当前的宿主机 - 最后,宿主机通过 session 映射
192.168.78.3:66666<->10.0.2.15:77777,最终将数据反馈给 veth1 既 192.168.78.3,这样 namespace ns1 就获得了外网主机反馈的数据。
参考设计 veth-internet,其外网主机的反馈流程既是将流程反向即可。